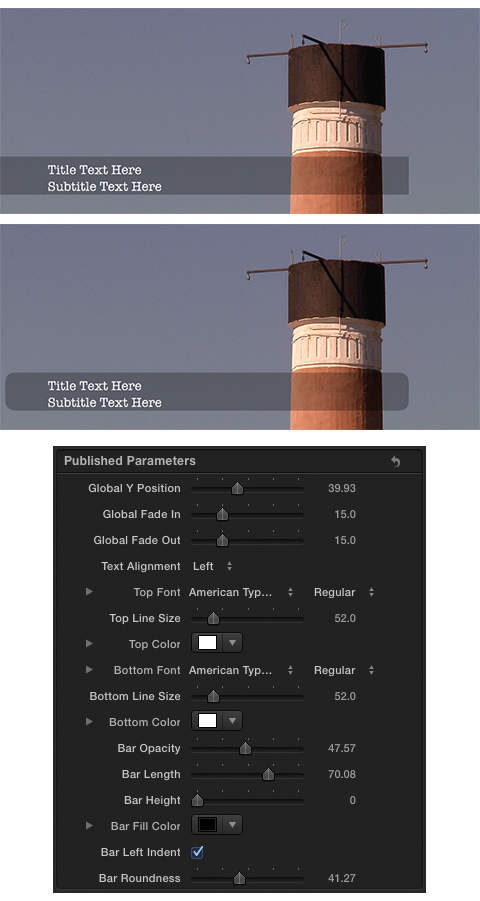
I was just reading Chris Curran’sDaily Goody segment, published today. The piece is titled Balancing the Levels of All Voices. Chris explains the importance of consistent dialogue levels across multiple participants, and shares various methods to achieve this.
Chris states in his second tip:
>>>“Another way to quickly balance the levels of various participants is to process each participants track to be the same LUFS level. This will make them close to level, but you will always want to adjust the levels slightly using your ears. Because even when the LUFS level of two different voices is the same, the perceived loudness of each voice can differ due to things like proximity to the mic, dynamic range, frequency response of the mic, the timbre of individual voices, etc. So it’s a handy practice to set the LUFS level of each participant to the same value, but then you still have to use your ears.”<<<
Good advise IMHO. Here’s my perspective …
The term LUFS Level is a generalization. It requires clarification.
There are 3 notable measurement descriptors that indicate perceptual Loudness in LUFS/LKFS (or LU’s when using a relative scale):
• Integrated Loudness (also referred to as Program Loudness)
• Short Term Loudness
• Momentary Loudness
Their distinguishing attributes are distinct time and/or averaging intervals: Integrated (cumulative measurement from start to finish), Short Term (3 sec.), and Momentary (400ms). It’s important to recognize the significance of each descriptor.
As well, (and Chris alludes to this in his piece) – you must recognize how a consistent Integrated Loudness measurement across multiple spoken word segments (or session participants) does not necessarily guarantee suitable matched level perception and/or optimized intelligibility.
Remember – Integrated Loudness represents a cumulative measurement from start to finish. For 100% accuracy – the piece must be measured in it’s entirety. Also, the descriptor does not reflect inherent dynamic attributes and/or inconsistencies that my in turn marginalize attempts to optimize perception.
With this in mind, if you choose to use Integrated Loudness as a perceptual Loudness matching indicator – audio optimization (compression, etc.) and target accuracy must be applied and established before relying on any common Integrated Loudness measurement.
What about Short Term/Momentary Loudness?
The 3 sec. averaging interval of the Short Term Loudness descriptor indicates an active, foreground measurement. It is highly useful when analyzing the loudness consistency of spoken word/dialogue. Momentary Loudness will provide even finer “detail” – once again due to it’s inherent averaging interval (400ms).
To summerize: “LUFS Level” is a generalization. As noted there are 3 descriptors (Integrated, Short Term, Momentary). Short Term and Momentary Loudness are useful indicators for the establishment of spoken word consistency. Learn how to use a Loudness Meter (online or offline) to closely monitor each descriptor.
With regards to Loudness Normalization – some processing tools such as RX Loudness Control by iZotope (AAX/Pro Tools only) support user defined Short Term and Momentary Loudness targeting within a certain tolerance range.
These options, along with the ubiquitous Integrated Loudness definition (and of course subjective audio processing) should provide everything you need in your quest to achieve optimized dialogue.
LevelView by Grimm Audio is a highly functional and well designed real time Loudness Meter.
Here are the details:
LevelView features a unique multifaceted Rainbow Meter. Clicking the Rainbow display toggles the Meter scale (EBU +9 or EBU +18).
There are three compliance modes: EBU R128, ATSC A/85, and a custom User specification (Gated or Ungated). The Rainbow Meter displays a Relative Scale. Consequentially the defined target will be equivalent to 0 LU.
The upper blue Rainbow arc represents Short Term Loudness measured within a 3 sec. time frame. The inward blue arcs indicate slower time frame variances (10, 30, 90, and 270 seconds).
The arced needle meter located above the Rainbow Meter represents the Momentary Loudness measured within a 400ms time frame.
Visual dots displayed (and held) on both the Momentary and Short Term Loudness indictor plots represent the maximum values for each descriptor. Both indicators will shift to orange when their values exceed recognized guidelines (+8 max M, and +6 Max S).
The numerical descriptor table features a large Integrated Loudness value. This may display an Absolute Scale value in LUFS, or a Relative Scale value in LU’s. Clicking the descriptor text toggles it’s view.
Additional numerical descriptors include maximum Momentary Loudness (max M), maximum Short Term Loudness (max S), LRA (Loudness Range), PLR (Peak to Loudness Ratio), and maximum True Peak (max TP). Clicking the max TP descriptor text will toggle the measurement algorithm and display max TP or max SP (Sample Peak). Descriptors will shift to orange when a displayed value exceeds recognized or specification guidelines.
The graph located at the lower left is the Loudness Range histogram. It displays the distribution of the measured Loudness over time. The data will indicate whether further dynamic range compression may be necessary.
LevelView supports Manual start and stop measurements. Setting the meter to Auto will force it to follow the host DAW’s transport. In essence the meter will automatically start/stop and reset based on the status of the transport.
Link mode records and stores data continuously. This allows the operator to revert back in time and re-measure a passage without resetting the stored measurements. In the event a passage is skipped, a gap warning will appear in orange. Re-measurement of a skipped segment will clear the gap warning. The Stop button resets the memory. Note the LevelView documentation indicates that the host “must provide time code for the Link function to work.”
It is possible to run various connected (Host and Client) instances of LevelView on a network or over the Internet. I will be testing these options in the near future.
LevelView is available as an AU, VST, or AAX Plugin. The AU and VST versions support (5.1) Surround Sound measurement. The meter conforms to the SMPTE/ITU channel matrix standard (L-R-C-LFE-Ls-Rs).
The meter may also run in a stand-alone mode with no DAW dependency. I/O configuration options are provided.
My Assessment:
I like this meter and I appreciate it’s unique design and accuracy. The networking options, support for Surround Sound, and stand-alone capability make it highly flexible and well worth it’s reasonable cost ($70 U.S. at Don’tCrack). I’m happy to recommend it.
Improvements I’d like to see:
– Scaleable UI
– Option to define a custom Maximum True Peak in the User mode (currently it defaults to -1.0 dBTP)
– I continue to endorse -16.0 LUFS for (stereo) Podcast distribution. If meeting this target requires an excessive amount of limiting, a slightly lower target is a viable option. However from my perspective a -20.0 LUFS spoken word piece consumed in a less than ideal environment on a mobile device would be problematic. I’m comfortable supporting upwards of a -2.0 LU deviation from the recommended -16.0 LUFS target (when applicable).
**Note mono files require a -3 LU offset to establish perceptual equivalence to stereo file targets.
– Loudness Range (LRA) is a statistical representation of Loudness distribution and/or the Loudness measurement. An LRA no higher than 8 LU will help optimize intelligibility by restricting dynamics and/or wide variations in Loudness over time.
– Networks and Catalog based program sets managed by indie producers must institute Program Loudness consisctency across all distributed media. This will free listeners from making constant playback volume adjsutments when listening to several programs in succession. Up to 1.0 LU tolerance (+/-) is reasonable. However upside Program Loudness should never exceed -16.0 LUFS.
– Without sufficient headroom – lossy, low bitrate encoding may generate peak levels that exceed a compliance ceiling and/or introduce distortion. -1.5 dBTP is the favored maximum ceiling prior to lossy coding. Of course a lesser value (e.g -2.0 dBTP) is appropriate. However, a peak ceiling below -3.0 dBTP may indicate excessive limiting. This should be avoided.
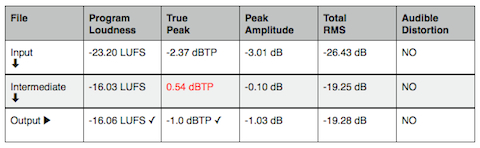
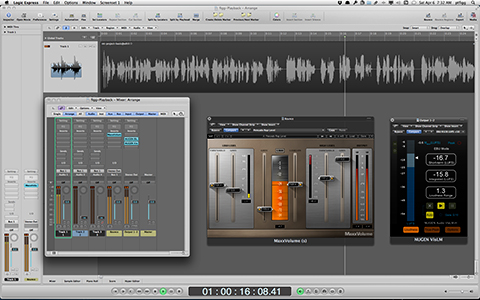
The attached image displays a processing workflow designed to optimize Spoken Word intelligibility. The workflow also demonstrates a realtime example of Integrated Loudness compliance targeting.
There are 7 reference point Sections worth noting:
Section A includes the Adobe Audition Effects Rack Signal Level Meters indicating the source (Input) level and the (Output) level. The Output level reflects the results of the workflow’s inserted plugins. The chain includes a Compressor, a Limiter, and a Loudness Meter. Note the level meters indicate signal level. They do not indicate or represent perceptual Loudness.
Section B displays the gain reduction applied by the Compressor at the current position of the playhead. For the test/source audio I determined an average of 6dB of gain reduction would yield acceptable results. The purpose of this stage is to reduce the dynamic range and/or dynamic structure of the Spoken Word resulting in optimized intelligibility AND to prevent excessive down stream limiting. This is an important workflow element when preparing Spoken Word audio for Internet/Mobile, and Podcast distribution.
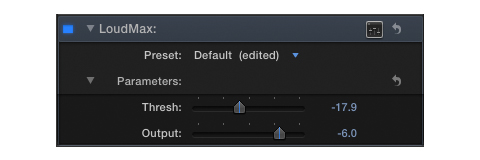
Section C includes my subjective limiting parameters. The Limiter will add the required amount of gain to achieve a -16.0 LUFS deliverable while adhering to a -1.5 dBTP (True Peak Max). If the client, platform, or workflow requires an alternative Loudness target and/or Maximum True Peak ceiling – the parameters and their mathematical relationship may be altered for customized targeting. Please note the Maximum True Peak referenced in any spec. is more of a ceiling as opposed to a target. In essence the measured signal level may be lower than the specified maximum.
Section D indicates the amount of limiting that is occurring at the current position of the playhead.
Section E displays the user defined Integrated Loudness target located above the circular Momentary Loudness LED (12 o’clock position). The defined Integrated Loudness target is also visually represented by the Radar’s second concentric circle. The Radar display indicates the Short Term Loudness measured over time within a 3 sec. window. The consistency of the Short Term Loudness is evident indicating optimized intelligibility.
Section F displays the unprocessed source audio that lacks optimization for Internet/Mobile, and Podcast distribution. Any attempt to consume the audio in it’s current state in a less than ideal listening environment will result in compromised intelligibility. Mobile device consumption in like environments will exacerbate compromised intelligibility.
Section G displays the processed/optimized audio suitable for the noted distribution platform. The Integrated Loudness, True Peak, and LRA descriptors now satisfy compliance targets. Notice there is no indication of excessive limiting.
Logic and Audition users will be familiar with the term Bounce to Track. This process allows the user to perform an Off-line Mixdown of a selected group of Session Tracks without physically exporting. In most cases the Mixdown appears on a supplemental target Track.
Bouncing Off-line is a time saver. However it can be precarious. It would be irresponsible to submit a finished piece of audio to a client without 100% conformation the bounced delivery file (most likely slated for distribution) is glitch free. In essence it is imperative to throughly check your piece prior to submission.
Off-line Bounce (aka Bounce to Disk) was once notoriously absent from Pro Tools. Avid finally implemented support a few years ago.
In professional Post Production, engineers may perform a real time (On-line) Bounce of a mix Session. The process is commonly referred to as Printing. It requires the operator to sit through the Session in it’s entirety.
Besides glitch detection capabilities, it is possible to edit clips before the playhead reaches their location. As well, you can edit clips and/or sub-segments within a previously completed Print and only re-Print the manipulated segment.
So how is this done? Simple – if the DAW or Interface supports it.
For instance in Pro Tools the user can assign Bus outputs to the input of a standard Audio Track. The key is you can ARM a standard Audio Track to record any signal that is passing through it. This would be the Print Track.
Adobe Audition CC does not support direct Bus Output —>> Audio Track assignments. However, it is still possible to implement a Print workflow (see attached image). You will need a supported Audio Interface with a Mix Return. Simply assign all Session Tracks and Buses to the Main Output. Then add a supplemental Audio Track. Set it’s input to Mix Return. ARM the Track to record and fire away.
I thought I’d revisit various aspects of Loudness Meter Absolute/Relative Scale correlation, and provide a visual representation of a real time processing Session with both Scales active.
Descriptors and Scales
Modern Loudness Meters display various descriptors including Program Loudness – also referred to as Integrated Loudness. There are two scales that can be used to display measured Program or Integrated Loudness over time …
The most common is an Absolute Scale, displayed in LUFS or LKFS. LUFS refers to Loudness Units relative to Full Scale. LKFS refers to Loudness Units K-Weighted relative to Full Scale. There is no difference in the perceptual measured loudness between both descriptor references.
It is also possible to measure and display Integrated/Program Loudness as Loudness Units (or LU’s) on a Relative Scale where 1LU == 1 dB.
When shifting to a Relative Scale, the 0 LU increment is always equivalent to the Meter’s user defined or spec. defined Absolute Loudness target.
For example, in an R128 -23.0 LUFS Absolute Scale workflow, setting the Meter to display a Relative Scale changes the target to 0 LU.
So – if a piece of measured audio checks in at -23.0 LUFS on an Absolute Scale, it would be perceptually equal to measured audio checking in at 0 LU on a Relative Scale.
Likewise if the Meter’s Absolute Scale target is set to -16.0 LUFS, it will correlate to 0 LU on a Relative Scale. Again both would reflect perceptual equivalence.
All broadcast delivery specifications suggest Absolute Scale Integrated Loudness targets. However, for any number of subjective reasons – many operators prefer to use the alternative Relative Scale and “mix or master to 0 LU.”
Please note Loudness Units are also the proper way in which to describe Loudness differentials between two programs. For instance, “Program (A) is +2 LU louder than Program (B).” One might also describe gain offsets in LU’s as opposed to dB’s.
LU Meter
Hornet Plugins recently released Hornet LU Meter. This tool is a Loudness Meter plugin designed to measure and display Integrated/Program Loudness within a 400ms time window. This measurement represents the Momentary Loudness descriptor.
The Meter is indeed nifty and affordable. However there is one sort of caveat worth noting: As the name suggests, it is an LU Meter. In essence Integrated (Momentary) Loudness measurements are solely displayed on a Relative Scale.
Session
The displayed Session (image) consists of a single mono VO clip. The objective is to print a processed stereo version in RT checking in at -16.0 LUFS with a maximum True Peak no higher than -2.0 dBTP.
The output of the mono VO track is routed to a mono Auxiliary Input track titled Normalize. If you are not familiar with Pro Tools, an Auxiliary Input track is not the same as an Auxiliary Send. Auxiliary Input tracks allow the user to pass signal using buses, insert plugins, and adjust level. They are commonly used to create sub-mixes.
I’ve inserted a Compressor and a Limiter on the Normalize Auxiliary Input track. The processed audio is passing through at -19.0 LUFS (mono).
The audio is then routed to a second (now stereo) Auxiliary Input track titled Offset. I use the track fader to apply a +3 dB gain offset, This will reconstitute the loss of gain that occurs on center panned mono tracks. The attenuation is a direct result of the Pro Tools Pan Depth setting.
The signal flow/output is now passing -16.0 LUFS audio. It is routed to a standard audio track titled Print. When this track is armed to record, it is possible to initiate a realtime bounce of the processed/routed audio.
The Meters
Notice the instances of the Hornet LU Meter and TC Electronics Loudness Radar. Both Meters are inserted on the Master Bus and are measuring the session’s Master Output.
I set the Reference (target) on the Hornet LU Meter to -16.0 LUFS. In essence 0 LU on it’s Relative Scale represents -16.0 LUFS.
Conversely the TC Electronic Meter is configured to display Absolute Scale measurements. The circular LED that borders the Radar area indicates Momentary Loudness. The defined Integrated Loudness target is displayed under the arrow at the 12 o’clock position.
Remember the Hornet LU Meter solely displays Momentary Loudness. If you compare it’s current reading to the indication of Momentary Loudness on the TC Electronic Meter, the relationship between Relative Scale and Absolute Scale measurement is clearly indicated. Basically the Hornet Meter registers just below 0 LU. The TC Electronic Meter registers just below -16.0 LUFS.
I will say if you are comfortable monitoring real time Momentary Loudness and understand Relative/Absolute Scale correlation, the Hornet tool is quite useful. In fact it contains additional features such as Grouping, auto/manual Gain Compensation, and auto-Maximum Peak protection.
Additional insight on the K-weighting Curve or K-weighted filtering:
K-weighting suggests de-emphasized low frequencies by way of a high-pass filter. A high-shelving filter is applied to the upper frequency range, and the measured data is averaged.
TC Electronic describes applied K-weighting on audio channels as a “method to build a bridge between subjective impression and objective measurement.”
This is a re-post of an article that I published in October, 2015 …
In a recent Midroll article titled “Why Programmatic Ads Aren’t Necessarily Great for Podcasting,” the staff writer states:
“A number of players in the Podcasting and advertising industries are making bets on programmatic Ad delivery — dynamically inserting Ads into a Podcast as the episode is downloaded. It’s an understandable temptation, but we at Midroll see some tradeoffs.”
I wonder how networks will handle potential perceived Loudness inconsistencies between produced Ads and new or preexisting programs?
I’ve mentioned my past affiliation with IT Conversations and The Conversations Network, where I was the lead post audio engineer from 2005-2012. Executive Director Doug Kaye built a proprietary content management system and infrastructure that included an automated component based Show Assembly System. Audio components were essentially audio clips (Intros, Outros, Ads, Credits. etc.) combined server side into Podcasts in preparation for distribution.
One key element in this implementation was the establishment of perceived Loudness consistency across all submitted audio components. This was accomplished by standardizing an average Loudness Target using a proprietary software RMS Normalizer to process all server side audio components prior to assembly. (Loudness Normalization is now the recommended process for Integrated Loudness targeting and consistency).
Due to this consistency, all distributed Podcasts were perceptually equal with regard to Integrated or Program Loudness upon playback. This was for the benefit of the listener, removing the potential need to make constant playback volume adjustments within a single program and throughout all programs distributed on the network.
Regarding Programmatic Ad insertion, I have yet to come across a Podcast Network that clearly states a set Integrated Loudness Target for submitted programs. (A Maximum True Peak requirement is equally important. However this descriptor has no effect on perceptual Loudness consistency).
Due to the absence of any suggested internal network guidelines or any form of standardized Loudness Normalization, dynamic Ad insertion has the potential to ruin the perceptual consistency within single programs and throughout the contents of an entire network.
Many conscientious independent producers have embraced the credible -16.0 LUFS Integrated Loudness Target for stereo Internet/ Mobile/Podcast audio distribution (the perceptual equivalent for mono distribution is -19.0 LUFS). It’s far from a requirement, and nothing more than a suggested guideline.
My hope is Podcast Networks will begin to recognize the advantages of standardization and consider the adoption of the -16.0 LUFS Integrated Loudness Target. Dynamically inserted Ads must be perceptually equal to the parent program. Without a standardized and pre-disclosed Integrated Loudness Target, it will be near impossible to establish any level of distribution consistency.
Below I’ve listed a few Adobe Audition CC (ver.2015.2.1) features/options that may be obscure and perhaps underutilized.
Usability
1- Maximize Active Frame (⌘↓). This command toggles full screen display accessibility of the active (blue outlined) UI Panel.
2- Lock In Time (Multitrack). When activated, selected clips are pinned to their current location. I mapped ⌥⌘L for this function.
3- Group (⌘G) (Multitrack). Multiple clips will be congregated and may be repositioned cumulatively.
4- Suspend Groups (⏎⌘G) (Multitrack). This function temporarily deactivates the Group. Actually, this command toggles the behavior between deactivate and activate. There are also options to Remove Focus Clip from Group and Ungroup Selected Clips. They both support custom shortcut mapping,
5- Right + Click on any Clip’s Fade Handle (Multitrack) to display the following customization menu:
– No Fade
– Fade In/Out
– Crossfade
– Symmetrical
– Asymmetrical
– Linear
– Cosine
– Automatic Crossfade Enabled
6- Bounce to New Track (Multitrack). This feature will process and combine multiple clips located on a single track or multiple tracks. This will free up system resources. The following options support custom shortcut mapping:
– Selected Track
– Time Selection
– Selected Clips In Time Selection
– Selected Clips Only
7- Convert To Unique Copy (Multitrack). This function creates a sub clip derived from the original trimmed source clip. Media Handles are no longer accessible in the converted copy (Multitrack and/or Waveform Editor environments). I mapped ⌥⌘C for this function.
Editing
1- Time Selection in all Tracks (Multitrack). This is a Ripple Delete variation (⏎⌘⌦) that will retain clip relevant Marker position(s).
2- Split All Clips Under Playhead (Multitrack). I mapped ⌥⌘R for this function.
3- Merge Clips (remove thru edits) (Multitrack). I mapped ⌥⌘J for this function.
Mixer/Track Inserts and Sends
1- Individual Track supplied buttons will designate Sends and Inserts as Pre or Post Fader.
Markers
1- Markers implemented in the Waveform Editor may be Merged thus allowing easy selection of encapsulated audio.
2- Selected Range Markers present in the Waveform Editor may be exported as individual clips.
3- Selected Range Markers present in the Waveform Editor may be added to a Playlist where they may be reordered for auditioning.
Exporting
1- The (Multitrack) Session Export Dialog includes user defined Mixdown options:
– Master: Stereo, Mono, or 5.1
– Signal present on individual Tracks
– Signal present on individual Busses
2- Export with Adobe Media Encoder (Multitrack). This Export option runs Media Encoder and requires the user to select a predefined Media Encoder preset. Routing options are available as well.
Adobe Audition and Logic Pro X include Pan Mode preference options that determine track output gain for center panned mono clips included in stereo sessions. These options are often the source of confusion when working with a combination of mono and stereo clips, especially when clips are pre-Loudness Normalized prior to importing.
In Audition, the Left/Right Cut (Logarithmic) option retains center panned mono clip gain. The -3.0 dB Center option, which by the way is customizable – will attenuate center panned mono clip gain by the specified dB value.
For example if you were targeting -16.0 LUFS in a stereo session using a combination of pre-Loudness Normalized clips, and all channel faders were set to unity – the imported mono clips need to be -19.0 LUFS (Integrated). The stereo clips need to be -16.0 LUFS (Integrated). The Left/Right Cut Pan Mode option will not alter the gain of the center panned mono clips. This would result in a -16.0 LUFS stereo mixdown.
Conversely the -3.0 dB Center Pan Mode option will apply a -3 dB gain offset (it will subtract 3 dB of gain) to center panned mono clips resulting in a -19.0 LUFS stereo mixdown. In most cases this -3 LU discrepancy is not the desired target for a stereo mixdown. Note 1 LU == 1 dB.
As stated Logic Pro X provides a similar level of Pan Mode flexibility. I’ve also tested Reaper, and it’s options are equally flexible.
Pro Tools
Pro Tools Pan Mode support (they call it Pan Depth) is somewhat restricted. The preference is limited to Center Pan Mode, with selectable dB compensation options (-2.5 dB, -3.0 dB, -4.5 dB, and -6.0 dB).
There are several ways to reconstitute the loss of gain that occurs in Pro Tools when working with center panned mono clips in stereo sessions. One option would be to duplicate a mono clip and place each instance of it on hard-panned discrete mono tracks (L+R respectively). Routing the mono tracks to a stereo output will reconstitute the loss of gain.
A second and much more efficient method is to route all individual instances of mono session clips to a stereo Auxiliary Input, and use it to apply the necessary compensating gain offset before the signal reaches the stereo Master Output. The gain offset can be applied using the Aux Input channel fader or by using an inserted gain trim plugin. Stereo clips included in the session can bypass this Aux and should be directly routed to the stereo Master Output. In essence stereo clips do not require compensation.
Example Session
Have a look at the attached Pro Tools session snapshot. In order to clearly display the signal path relative to it’s gain, I purposely implemented Pre-Fader Metering.
Notice how the mono spoken word clip included on track 1 is routed (by way of stereo Bus 1-2) to a stereo Auxiliary Input track (named to Stereo). Also notice how the stereo signal level displayed by the meters on the Stereo Auxiliary Input track is lower than the mono source that is feeding it. The level variation is clear due to Pre-Fader Metering. It is the direct result of the session’s Pan Depth setting that is subtracting -3dB of gain on this center panned mono track.
Next, notice how the signal level on the Master Output has been reconstituted and is in fact equal to the original mono source. We’ve effectively added +3dB of gain to compensate for the attenuation of the original center panned mono clip. The +3dB gain compensation was applied to the signal on the Auxiliary Input track (via fader) before routing it’s output to the stereo Master Output.
So it’s: Center Panned mono resulting in a -3dB gain attenuation —>> to a stereo Aux Input with +3dB of gain compensation —>> to stereo Master Output at unity.
In case you are wondering – why not add +3dB of gain to the mono clip and bypass all the fluff? By doing so you would be altering the native inherent gain structure of the mono source clip, possibly resulting in clipping. My described workflow simply reconstitutes the attenuated gain after it occurs on center panned mono clips. It is all necessary due to Pro Tool’s Pan Depth methods and implementation.
In a professional workflow Dither will be applied to audio clips (or mixes) when reducing word length. This process will mitigate errors that occur due to the subtraction of digital audio bits. I thought I’d cover the basics.
Digital Audio
Digital Audio incorporates individual samples consisting of bits created by the process of Quantization. This is essentially the conversion of a continuous, linear range of values present in analog audio into a fixed range of discrete values. Bit Depth (a.k.a. Word Length or Resolution) represents the number of bits stored in a sample’s measure of amplitude. It indicates the extent of inherent vertical precision. Higher bit depths (or bits per sample) encompass improved vertical dynamic resolution resulting in an extended Dynamic Range.
1 bit = 6dB of Dynamic Range. Theoretically 16bit audio has a quantified Dynamic Range of 96 dB. 24 bit audio has a quantified Dynamic Range of 144 dB. However, in order to accurately assess Dynamic Range we must also recognize the amplitude of the highest spectral component of the inherent noise floor. Specifically, where it resides relative to the maximum Peak value that a system is capable of reproducing. Dynamic Range is the measurement of this ratio or range.
Signal to Noise Ratio (SNR) is the quantified range between the nominal average signal level and the average level of the noise floor. Audio with an extended Dynamic Range will exhibit a higher SNR compared to audio with a reduced Dynamic Range. In essence 24 bit audio will allow you to work with additional headroom without any increase in noise compared to 16 bit audio.
Word Length Reduction
Truncation is the removal of bits with no compensating replacement. The repositioning of samples after converting to a lower resolution creates Quantization Errors resulting in audible artifacts and distortion. Dither is technology that adds minimal perceived noise to audio before word length reduction. This noise will mitigate (mask/remove) the audibility of distortion caused by Quantization Errors. The process preserves fidelity and Dynamic Range of audio throughout bit-depth conversion and/or bit-depth reduction exporting.
There is a trade off: you are replacing bad noise with alternative “good” noise that is smoother, less audible, and much more consistent.
Noise Shaping is a supplemental option that pushes noise into frequency ranges that are less audible to humans, thus allowing greater Dither with reduced perceptual noise.
(Take a look at the Noise Shaped frequency response curve in the attached image. There is a clear visual indication of increased gain at higher frequencies).
Podcasting
So what does this all mean for the typical Podcast Producer? Is Dither just another obscure aspect of professional Audio Mastering and/or Post Production that can be safely ignored?
Consider the following variables:
If you are recording spoken word using properly configured gear in a reasonably quiet and optimized environment – there is no discernible advantage recording 24-bit audio in preparation for 16-bit encoding and delivery. In my opinion 16-bit audio from acquisition to distribution will be more than adequate.
If you elect to record 24 bit audio, and you are not properly implementing word length reduction to 16 bit, you are essentially nulling the advantages of the original higher resolution audio. In essence fidelity degradation (artifacts/distortion) will occur due to the absence of efficient error masking. This is not my opinion – it is a fact.
Remember, I’m specifically referring to spoken word audio slated for Podcast distribution. If you are tracking music, well then by all means make full use of the advantages of higher resolution audio recording.
Consider this: The stand-alone version of iZotope’s Ozone 8 Mastering Suite processes all imported audio to 32 bit word length. The manual specifically states:
“Ozone processes files at 32-bit so Dither is desirable for files being exported to values lower than 32-bit …
… When exporting to a bit depth lower than 32-bit, checking this (Dither option) box will apply high-quality dithering to the exported file. This allows you to preserve the sound quality and dynamic range of a higher bit depth, when exporting the audio file to a lower bit depth.”
Most DAWS include Dither options. In some cases it’s by way of a plugin. You may also notice Dither options included in application Preferences or Export dialogs.
Hopefully after reading this article you will understand what Dither is, it’s purpose, and whether you should consider implementing it. Please note: Dither must be applied at the very last stage of any processing chain.
I’d like to share my observations and views on the recently published AES Technical Document AES TD1004.1.15-10 that specifics best practices for Loudness of Audio Streaming and Network File Playback.
The document is a collection of Loudness processing guidelines for diverse platform dependent media streaming and downloading. This would include music, spoken word, and possible high dynamic audio in video streams. The document credits some of the most well respected industry leading professionals, including Bob Katz, Thomas Lund, and Florian Camerer. The term “Podcast” is directly referenced once in the document, where the author(s) state:
“Network file playback is on-demand download of complete programs from the network, such as podcasts.”
I support the purpose of this document, and I understand the stated recommendations will most likely evolve. However in my view the guidelines have the potential to create a fair amount of confusion for producers of spoken word content, mainly Podcast producers. I’m specifically referring to the suggested 4 LU range (-16.0 to -20.0 LUFS) of acceptable Integrated Loudness Targets and the solutions for proper targeting.
Indeed compliance within this range will moderately curtail perceptual loudness disparities across a wide range of programs. However the leniency of this range is what concerns me.
I am all for what I refer to as reasonable deviation or “wiggle room” in regard to Integrated Loudness Target flexibility for Podcasts. However IMHO a -20 LUFS spoken word Podcast approaches the broadcast Loudness Targets that I feel are inadequate for this particular platform. A comparable audio segment with wide dynamics will complicate matters further.
I also question the notion (as stated in the document) of purposely precipitating clipping when adding gain “to handle excessive peaks.”
And there is no mention of the perceptual disparities between Mono and Stereo files Loudness Normalized to the same Integrated Loudness Target. For the record I don’t support mono file distribution. However this file format is prevalent in the space.
Perspective
I feel the document’s perspective is somewhat slanted towards platform dependent music streaming and preservation of musical dynamics. In this category, broad guidelines are for the most part acceptable. This is due to the wide range of production techniques and delivery methods used on a per musical genre basis. Conversely spoken word driven audio is not nearly as artistically diverse. Considering how and where most Podcasts are consumed, intelligibility is imperative. In my view they require much more stringent guidelines.
It’s important to note streaming services and radio stations have the capability to implement global Loudness Normalization. This frees content creators from any compliance responsibilities. All submitted media will be adjusted accordingly (turned up or turned down) in order to meet the intended distribution Target(s). This will result in consistency across the noted platform.
Unfortunately this is not the case in the now ubiquitous Podcasting space. At the time of this writing I am not aware of a single Podcast Network that (A) implements global Loudness Normalization … and/or … (B) specifies a requirement for Integrated Loudness and Maximum True Peak Targets for submitted media.
Currently Podcast Loudness compliance Targets are resolved by each individual producer. This is the root cause of wide perceptual loudness disparities across all programs in the space. In my view suggesting a diverse range of acceptable Targets especially for spoken word may further impede any attempts to establish consistency and standardization.
PLR and Retention of Music Dynamics
The document states: “Users may choose a Target Loudness that is lower than the -16.0 LUFS maximum, e.g., -18.0 LUFS, to better suit the dynamic characteristics of the program. The lower Target Loudness helps improve sound quality by permitting the programs to have a higher Peak to Loudness Ratio (PLR) without excessive peak limiting.”
The PLR correlates with headroom and dynamic range. It is the difference between the average Loudness and maximum amplitude. For example a piece of audio Loudness Normalized to -16.0 LUFS with a Maximum True Peak of -1 dBTP reveals a PLR of 15. As the Integrated Loudness Target is lowered, the PLR increases indicating additional headroom and wider dynamics.
In essence low Integrated Loudness Targets will help preserve dynamic range and natural fidelity. This approach is great for music production and streaming, and I support it. However in my view this may not be a viable solution for spoken word distribution, especially considering potential device gain deficiencies and ubiquitous consumption habits carried out in problematic environments. In fact in this particular scenario a moderately reduced dynamic range will improve spoken word intelligibility.
Recommended Processing Options and Limiting
If a piece of audio is measured in it’s entirety and the Integrated Loudness is higher than the intended Target, a subtractive gain offset normalizes the audio. For example if the audio checks in at -18.0 LUFS and you are targeting -20.0 LUFS, we simply subtract 2 dB of gain to meet compliance.
Conversely when the measured Integrated Loudness is lower than the intended Target, Loudness Normalization is much more complex. For example if the audio checks in at -20.0 LUFS, and the Integrated Loudness Target is -16.0 LUFS, a significant amount of gain must be added. In doing so the additional gain may very well cause overshoots, not only above the Maximum True Peak Target, but well above 0dBFS. Inevitably clipping will occur. From my perspective this would clearly indicate the audio needs to be remixed or remastered prior to Loudness Normalization.
Under these circumstances I would be inclined to reestablish headroom by applying dynamic range compression. This approach will certainly curtail the need for aggressive limiting. As stated the reduced dynamic range may also improve spoken word intelligibility. I’m certainly not suggesting aggressive hyper-compression. The amount of dynamic range reduction is of course subjective. Let me also stress this technique may not be suitable for certain types of music.
Additional Document Recommendations and Efficiency
The authors of the document go on to share some very interesting suggestions in regard to effective Loudness Normalization:
1) “If level has to be raised, raise until it reaches Target level or until True Peak reaches 0 dBTP, whichever occurs first. Thus, the sound quality will be preserved, without introducing excessive peak limiting.”
2) “Perform what is noted in example 1, but keep raising the level until the program level reaches Target, and apply either peak limiting or allow some clipping to handle excessive peaks. The advantage is more consistent loudness in the stream, but this is a potential sonic compromise compared to example 1. The best way to retain sound quality and have more consistent loudness is by applying example 1 and implementing a lower Target.”
With these points in mind, please review/demo the following spoken word audio segment. In my opinion the audio in it’s current state is not optimized for Podcast distribution. It’s simply too low in terms of perceptual loudness and too dynamic for effective Loudness Normalization, especially if targeting -16.0 LUFS. Due to these attributes suggestion 1 above is clearly not an option. In fact neither is option 2. There is simply no available headroom to effectively add gain without driving the level well above full scale. Peak limiting is unavoidable.
I feel the document suggestions for the segment above are simply not viable, especially in my world where I will continue to recommend -16.0 LUFS as the recommended Target for spoken word Podcasts. Targeting -18.0 LUFS as opposed to -16.0 LUFS is certainly an option. It’s clear peak limiting will still be necessary.
Below is the same audio segment with dynamic range compression applied before Loudness Normalization to -16.0 LUFS. Notice there is no indication of aggressive limiting, even with a Maximum True Peak of -1.7 dBTP.
Regarding peak limiting the referenced document includes a few considerations. For example: “Instead of deciding on 2 dB of peak limiting, a combination of a -1 dBTP peak limiter threshold with an overall attenuation of 1 dB from the previously chosen Target may produce a more desirable result.”
This modification is adequate. However the general concept continues to suggest the acceptance of flexible Targets for spoken word. This may impede perceptual consistency across multiple programs within a given network.
Conclusion
The flexible best practices suggested in the AES document are 100% valid for music producers and diverse distribution platforms. However in my opinion this level of flexibility may not be well suited for spoken word audio processing and distribution.
I’m willing to support the curtailment of heavy peak limiting when attempting to normalize spoken word audio (especially to -16.0 LUFS) by slightly reducing the intended Integrated Loudness Target … but not by much. I will only consider doing so if and when my personal optimization methods prior to normalization yield unsatisfactory results.
My recommendation for Podcast producers would be to continue to target -16.0 LUFS for stereo files and -19.0 LUFS for mono files. If heavy limiting occurs, consider remixing or remastering with reduced dynamics. If optimization is unsuccessful, consider lowering the intended Integrated Loudness Target by no more than 2 LU.
A True Peak Maximum of <= -1.0 dBTP is fine. I will continue to suggest -1.5 dBTP for lossless files prior to lossy encoding. This will help ensure compliance in encoded lossy files. What’s crucial here is a full understanding of how lossy, low bit rate coders will overshoot peaks. This is relevant due to the ubiquitous (and not necessarily recommended) use of 64kbps for mono Podcast audio files.
Let me finish by stating the observations and recommendations expressed in this article reflect my own personal subjective opinions based on 11 years of experience working with spoken word audio distributed on the Internet and Mobile platforms. Please fell free to draw your own conclusions and implement the techniques that work best for you.
I’ve discussed the reasons why there is a need for revised (optimized) Loudness Standards for Internet and Mobile audio distribution. Problematic (noisy) consumption environments and possible device gain deficiencies justify an elevated Integrated Loudness target. Highly dynamic audio complicates matters further.
In essence audio for the Internet/Mobile platform must be perceptually louder on average compared to audio targeted for Broadcast. The audio must also exhibit carefully constrained dynamics in order to maintain optimized intelligibility.
The recommended Integrated Loudness targets for Internet and Mobile audio are -16.0 LUFS for stereo files and -19.0 LUFS for mono. They are perceptually equal.
In terms of Dynamics, I’ve expressed my opinion regarding compression. In my view spoken word audio intelligibility will be improved after careful Dynamic Range Compression is applied. Note that I do not advocate aggressive compression that may result in excessive loudness and possible quality degradation. The process is a subjective art. It takes practice with accessibility to well designed tools along with a full understanding of all settings.
I thought I would discuss various aspects of Podcast audio Dynamics. Mainly, the potential problematic significance of wide Dynamics and how to quantify aspects as such using various descriptors and measurement tools. I will also discuss the benefits of Dynamic Range management as a precursor to Loudness Normalization. Lastly I will disclose recommended benchmarks that are certainly not requirements. Feel free to draw your own conclusions and target what works best for you.
Highly Dynamic Audio in Noisy Environments
At it’s core extended or Wide Dynamic Range describes notable disparities between high and low level passages throughout a piece of audio. When this is prevalent in a spoken word segment, intelligibility will be compromised – especially in situations where the listening environment is less than ideal.
For example if you are traveling below Manhattan on a noisy subway, and a Podcast talent’s delivery is inconsistent, you may need to make realtime playback volume adjustments to compensate for any inconsistent high and low level passages.
As well – if the Integrated Loudness is below what is recommended, the listening device may be incapable of applying sufficient gain. Dynamic Range Compression will reestablish intelligibility.
From a post perspective – carefully constrained dynamics will provide additional headroom. This will optimize audio for further down stream processing and ultimately efficient Loudness Normalization.
Dynamic Range Compression and Loudness Normalization
I would say in most cases successful Loudness Normalization for Broadcast compliance requires nothing more than a simple subtractive gain offset. For example if your mastered piece checks in at -20.0 LUFS (stereo), and you are targeting R128 (-23.0 LUFS Integrated), subtracting -3 LU of gain will most likely result in compliant audio. By doing so the original dynamic attributes of the piece will be retained.
Things get a bit more complicated when your Integrated Loudness target is higher than the measured source. For example a mastered -20.0 LUFS piece will require additional gain to meet a -16.0 LUFS target. In this case you may need to apply a significant amount of limiting to prevent the Maximum True Peak from exceeding your target. In essence without safeguards, added gain may result in clipping. The key is to avoid excessive limiting if at all possible.
How do we optimize audio before a gain offset is applied?
I recommend applying a moderate to low amount of (global) final stage Dynamic Range Compression before Loudness Normalization. When processing highly dynamic audio this final stage compression will prevent instances of excessive limiting. The amount of compression is of course subjective. Often a mere 1-2 dB of gain reduction will be sufficient. Effectiveness will always depend on the attributes of the mastered source audio before L.Normalizing.
I carefully manage spoken word dynamics throughout client project workflows. I simply maintain sufficient headroom prior to Loudness Normalization. In most cases I am able to meet the intended Integrated Loudness and Maximum True Peak targets (without limiting) by simply adding gain.
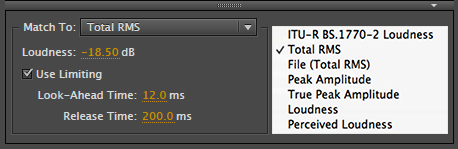
RX Loudness Control
By design iZotope’s RX Loudness Control also applies compression in certain instances of Loudness Normalization. I suggest you read through the manual. It is packed with information regarding audio loudness processing and Loudness Normalization.
iZotope states the following:
“For many mixes, dynamics are not affected at all . This is because only a fixed gain is required to meet the spec . However, if your mix is too dynamic or has significant transients, compression and/or limiting are required to meet Short-term/Momentary or True Peak parts of the spec.”
“RX Loudness Control uses compression in a way that preserves the quality of your audio . When needed, a compressor dynamically adjusts your audio to ensure you get the best sound while remaining compliant . For loudness standards that require Short-term or Momentary compliance, the compressor is engaged automatically when loudness exceeds the specified target.”
It’s a highly recommended tool that simplifies offline processing in Pro Tools. Many of it’s features hook into Adobe’s Premiere Pro and Media Encoder.
LRA, PLR, and Measurement Tools
So how do we quantify spoken word audio dynamics? Most modern Loudness Meters are capable of calculating and displaying what is referred to as the Loudness Range (LRA). This particular descriptor is displayed in Loudness Units (LU’s). Loudness Range quantifies the differences in loudness measurements over time. This statistical perspective can help operators decide whether Dynamic Range Compression may be necessary for optimum intelligibility on a particular platform. (Note in order to prevent a skewed measurement due to various factors – the LRA algorithm incorporates relative and absolute threshold gating. For more information: refer to EBU Tech doc 3342).
I will say before I came across sort of rule of thumb (recommended) guidelines for Internet and Mobile audio distribution, the LRA in the majority of the work that I’ve produced over the years hovered around 3-5 LU. In the highly regarded article Audio for Mobile TV, iPad and iPod, the author and leading expert Thomas Lund of TC Electronic suggests an LRA not much higher than 8 LU for optimal Pod Listening. Basically higher LRA readings suggest inconsistent dynamics which in turn may not be suitable for Mobile platform distribution.
Some Loudness Meters also display the PLR descriptor, or Peak to Loudness Ratio. This correlates with headroom and dynamic range. It is the difference between the Program (average) Loudness and maximum amplitude. Assuming a piece of audio has been Loudness normalized to -16.0 LUFS along with an awareness of a True Peak Maximum somewhere around -1.0 dBTP, it is easy to recognize the general sweet spot for the Mobile platform ->> (e.g. a PLR reasonably less than 16 for stereo).
Note that heavily compressed or aggressively limited (loud) audio will exhibit very low PLR readings. For example if the measured Integrated Loudness of a particular program is -10.0 LUFS with a Maximum True Peak of -1.0 dBTP, the reduced PLR (9) clearly indicates aggressive processing resulting in elevated perceptual loudness. This should be avoided.
If you are targeting -16.0 LUFS (Integrated), and your True Peak Maximum is somewhere between -1.0 and -3.0 dBTP, your PLR is well within the recommended range.
In Conclusion
An optimal LRA is vital for Podcast/Spoken Word distribution. Use it to gauge delivery consistency, dynamics, and whether further optimization may be necessary. At this point in time I suggest adhering to an LRA < 7 LU for spoken word.
LRA Measurements may be performed in real time using a compliant Loudness Meter such as Nugen Audio’s VisLM 2, TC Electronic’s LM2n Loudness Radar, and iZotope’s Insight (also check out the Youlean Loudness Meter). Some meters are capable of performing offline measurements in supported DAWs. There are a number of stand alone third party measurement options available as well, such as iZotope’s RX7 Advanced Audio Editor, Auphonic Leveler, FFmpeg, and r128x.
-paul.
***Please note I personally paid for my RX Loudness Control license and I have no formal affiliation with iZotope.
PRSS (Public Radio Satellite System) recently published Loudness Standardization parameters intended for contributing producers:
[– Target Loudness: Integrated loudness shall be -24 LUFS per program segment with a variance of ±2 LU. This will apply to speech and/or music elements.
[– Maximum Peak Level: Shall be no higher than -3 dBFS for sample peaks and shall be no higher than -2 dBTP for True Peaks.
To supplement the published standards, my twitter acquaintance and fellow Loudness advocate Rob Byers posted The Audio Producer’s Guide to Loudness on Transom.org.
The article documents the basics of Loudness Meters, measurement descriptors, and mixing best practices. It’s a viable guide for anyone planning to submit compliant audio for Public Radio distribution. Incidentally Rob is the Interim Director of Broadcast and Media Operations with Marketplace at American Public Media.
Anyway … I’d like to share my personal perspective regarding the differences between real time compliance mixing vs. compliance processing. I’m confident my subjective insight will prove to be useful for Public Radio Producers targeting the PRSS spec.
Internet/Mobile vs. Broadcast
I’ve stated that targeted (Integrated/Program) Loudness for Radio/Broadcast differs from what I consider suitable for audio distributed on the Internet. This includes streaming audio, video, and Podcasts. Basically audio mixed and/or Loudness Normalized to -23.0/-24.0 LUFS, targeted to comply with a Broadcast spec. is simply not loud enough for Internet distribution. This is due to various aspects of consumption, including device deficiencies and problematic ambiance in less than ideal listening environments. The Integrated Loudness target for Internet/Mobile audio is -16.0 LUFS with allowance for a reasonable deviation. True Peaks should not exceed -1.0 dBTP in lossy files. Some institutions suggest additional headroom.
Mixing for Compliance
I rarely mix audio in real time while attempting to meet Integrated and True Peak compliance targets. This method is acceptable. However there are a few caveats.
First, in order to arrive upon an accurate representation of Integrated Loudness, audio mixes must be measured in their entirety. You cannot spot check a few passages of a mix and estimate this descriptor. Needless to say this can be a time consuming process.
Secondly, in my view real time mixing for compliance is tedious and potentially inaccurate. What I recommend is to use both the Short Term and Integrated Loudness descriptors to sort of gauge the current state of the mix as playback progresses and ends. Once the mix has concluded – simply apply a global Gain Offset to the entire mix. This will shift the Integrated Loudness to your intended target. This is essentially one way to apply Loudness Normalization.
For example if a concluded mix checks in at -20.0 LUFS, and you are targeting -24.0 LUFS, prior to bouncing, a -4LU (dB) global Gain Offset would bring the mix into spec. (The process is discussed in this video highlighting the TC Electronic Loudness Radar Meter included in Adobe Audition and Premiere Pro. Of course any compliant Loudness Meter would be suitable).
By the way let’s not forget the importance of True Peak compliance for any standard. This descriptor will also need to be monitored and dealt with accordingly while mixing.
Trust Your Ears!
This second (and preferred) method of Loudness Normalization requires proper use of the most important tool(s) available to all of us in any mixing or post production environment … our ears. Producers need to learn how to take advantage of natural perception and also apply thoughtful processing to session clips with the intent to achieve a well balanced, good sounding mix. In doing so the use of a Loudness Meter becomes much less of a distraction.
Of course the presence of an inserted meter is a necessity, and it’s descriptors will (over time) display a clear indication of the state of the mix. Trust your ears!
Off-line Loudness Normalization
The workflow that I’m about to describe will reward producers with Loudness compliance flexibility throughout a mixing session. The key is upon completion, the mixed (and exported) audio will be processed off-line resulting in 100% compliance.
As noted, the global Gain Offset method for Loudness Normalization requires knowledge of existing Integrated Loudness prior to applying the necessary adjustments. The following variation shares the same requirement. However the Integrated Loudness and True Peak of the mixed-down audio will be calculated off-line as opposed real time. Let me stress the existing Integrated Loudness must be realized before we can move forward with any form of compliance processing. We will be targeting the PRSS specifications noted above.
FFMpeg:Cross Platform Support
There are many ways to measure audio off-line. The most accessible and economical cross-platform tool is the FFmpeg binary. Indeed this is a Command Line utility. Don’t fret! It’s not that big of a deal. You can easily download a pre-complied binary compatible with your current operating system. You simply point your command line syntax to the location of the binary, key in the path to the location of the file to be measured, and fire away.
Below is example syntax for Loudness Measurement. In this particular instance I point to the binary stored in a root, system wide folder. If you are running a Mac, it may be easier to simply place the binary on your Desktop. In this case you would point to the binary like this: ~/Desktop/ffmpeg … then continue with the remaining displayed syntax, replacing yourSourceFile.wav with the actual path of the file to be measured.
And here are the results. Notice the -19.9 LUFS Integrated Loudness (I), and the 1.8 dBFS (dBTP) True Peak (open the image for an extended view).
The PRSS spec. calls for -24.0 LUFS Integrated Loudness with Sample Peaks not exceeding -3.0 dB and True Peaks not exceeding -2.0 dBTP. In this measured example the audio is roughly +4LU louder than it should be and it is obviously clipped with it’s True Peak well above 0dBFS.
Setting Up The Normalization Session
In your preferred DAW, create a new stereo session and do the following:
[– Add a Stereo Audio Track, two Stereo AUX Input Channels (primary/secondary), and a Master Fader.
[– Route the Audio Track’s output to the input of the primary Aux Input Channel.
[– On the primary Aux Input Channel – first insert a Gain Trim plugin. Then insert a True Peak Limiter.
[– Now route the output of the primary Aux Input Channel to the input of the secondary Aux Input Channel.
[– Insert a second instance of a Gain Trim plugin on the secondary Aux Input Channel.
[– Route the processed signal to the Master Fader.
[– Set the True Peak Ceiling on the Limiter to -3.5dBTP. Set the Gain Trim inserted on the secondary Aux Input Channel to +1dB. Note that these settings are static and will never change.
Save the session as a Template.
Here is an example of how I do this in Pro Tools. Note that I have additional plugins inserted on the sessions’s Aux Input Channels. They are in fact deactivated. Please disregard them. I was using this example session for testing, using duplicate sets of plugins for various parameter adjustments. (click to enlarge).
Making it Work
Using the measured audio displayed above, note the Integrated Loudness (-19.9 LUFS). All you need to do is calculate an initial Gain Offset. This is the difference between the measured Integrated Loudness and -25.0. Add the mixed-down audio into the session’s Audio Track, and set the Gain Trim plugin inserted on the Primary Aux Input Channel to the calculated Gain Offset.
Bounce and you’re done.
Note that the initial Gain Offset will always be determined by calculating the difference between existing Integrated Loudness and -25.0. Once the core session Template is saved, subsequent use is simple: Measure mixed-down audio – Import audio into session – Calculate Gan Offset – Apply Offset to Primary Gain Trim – Bounce.
In order to understand the attributes of asymmetric waveforms, it’s important to clarify the differences between DC Offset and Asymmetry …
Waveform Basics
A waveform consists of both a Positive and Negative side, separated by a center (X) axis or “Baseline.” This Baseline represents Zero (∞) amplitude as displayed on the (Y) axis. The center portion of the waveform that is anchored to the Baseline may be referred to as the mean amplitude.
DC Offset
DC Offset occurs when the mean amplitude of a waveform is off the center axis due to differing amounts of the signal shifting to the positive or negative side of the waveform.
One common cause of this shift is when faulty electronics insert a DC current into the signal. This abnormality can be corrected in most file based editing applications and DAW’s. Left uncorrected, audio with DC Offset will exhibit compromised dynamic range and a loss of headroom.
Notice the displacement of the mean amplitude:
The same clip after applying DC Offset correction. Also, notice the preexisting placement of (+/-) energy:
Asymmetry
Unlike waveforms that indicate DC Offset, Asymmetric waveform’s mean amplitude will reside on the center axis. However the representations of positive and negative amplitude (energy) will be disproportionate. This can inhibit the amount of gain that can be safely applied to the audio.
In fact, the elevated side of a waveform will tap the target ceiling before it’s counterpart resulting in possible distortion and the loss of headroom.
High-pass filters, and aggressive low-end processing are common causes of asymmetric waveforms. Adding gain to asymmetric waveforms will further intensify the disproportionate placement of energy.
In this example I applied a high-pass filter resulting in asymmetry:
Broadcast Chains
Broadcast engineers closely monitor positive to negative energy distribution as their audio passes through various stages of processing and transmission. Proper symmetry aides in the ability to process a signal more effectively downstream. In essence uniform gain improves clarity and maximizes loudness.
Podcasts
In spoken word – symmetry allows the voice to ride higher in the mix with a lower risk of distortion. Since many Podcast Producers will be adding gain to their mastered audio when loudness normalizing to targets, the benefits of symmetric waveforms are obvious.
If an audio clip’s waveform(s) are asymmetric and the audio exhibits audible distortion and/or a loss of headroom, a Phase Rotator can be used to reestablish proper symmetry.
Below is a segment lifted from a distributed Podcast (full zoom out). Notice the lack of symmetry, with the positive side of the waveform limited much more aggressively than the negative:
The same clip after Phase Rotation:
(I processed the clip above using the Adaptive Phase Rotation option located in iZotope’s RX 4 AdvancedChannel Ops module.)
In Conclusion
Please note that asymmetric waveforms are not necessarily bad. In fact the human voice (most notably male) is often asymmetric by nature. If your audio is well recorded, properly processed, and pleasing to the ear … there’s really no need to attempt to correct any indication of asymmetry.
However if you are noticing abnormal displacement of energy, it may be worth looking into. My suggestion would be to evaluate your workflow and determine possible causes. Listen carefully for any indication of distortion. Often a slight EQ tweak or a console setting modification is all that may be necessary to make noticeable (audible) improvements to your audio.
iZotope has released a newly designed version of Ozone, their flagship Mastering processor. Notice I didn’t refer to Ozone [6] as a plugin? Well I’m happy to report that Ozone [6] is now capable to run independent of a DAW as a stand-alone desktop processor.
Besides the stand-alone option and striking UI overhaul, Ozone’s flexibility has been greatly enhanced with the addition of support to host third party Audio Units and VST plugins. Preliminary tests here indicate that it functions very well in the stand-alone mode. More on this in moment …
I’ve been a customer and supporter of iZotope since early 2005. If I remember correctly Ozone 3 was the first version that I had access to. In fact back in the early days of Podcasting, many producers purchased an Ozone license based on my endorsement. This was an interesting scenario all due to the fact that most of the people in the community who bought it – had no idea how to use it! And so a steady flow of user support inquiries began to trickle in.
I decided the best way to bring users up to speed was to design Presets. I would distribute the underlying XML file and have the users move it to the proper location on their system’s. After doing so, the Preset would be accessible within Ozone’s Preset Manager.
The complexity of the Presets varied. Some people wanted basic Band-Pass filters. Others requested the simulation of a broadcast chain that would result in a signature sound for their recorded voice. In fact I remember one particular instance where the user requested a Preset that would make him sound like an “AM Radio DJ”. So I went to work and I think I made him happy.
As Ozone matured, it’s level of complexity increased resulting in somewhat sluggish performance (at least for me). When iZotope released Alloy 2, I bought it – and found it to be much more responsive. And so I sort of moved away from Ozone, especially Ozone 5. My guess is if my system’s were a bit more robust, poor performance would be less of an issue. Note that my personal experience with Ozone was not necessarily the general concensus. Up to this latest release, the plugin was highly regarded with widespread use in the Mastering community.
Over the past 24 hours I’ve been paying close attention to how Ozone users are reacting to this new version. Note that a few key features have been removed. The Reverb module is totally gone. Gating/Expansion has been removed from the Dynamics Module, and the Dithering options have been minimized. The good news is these particular features are not game changers for me based on how I use this tool. I will say the community reaction has been tepid. Some users are passing on the release due to the omissions that I’ve mentioned and others that I’m sure I’ve overlooked.
For me personally – the $99 upgrade was a no-brainer. In my view the stand-alone functionality and the support for third party plugins makes up for what has been removed. In stand-alone mode you can import multiple files, save your work as projects, implement processing chains in a specific order, apply head/tail cuts/fades, and export your work.
Ozone [6] will accept WAV, AIFF, or MP3 files. If you are exporting to lossless, you can convert Sample Rates and apply Dither. This all worked quite well on my 2010 MacPro. In fact the performance was quite good, with no signs of sluggish performance. I did notice some problematic issues with plugin wrappers not scaling properly. Also the Plugin Manager displayed duplicates of a few plugins. This did not hinder performance in any way. In fact all of my plugins functioned well.
And so that’s my preliminary take. My guess is this new version of Ozone is well suited for advanced New Media Producers who have a basic understanding of how to process audio dynamics and apply EQ. Of course there’s much more to it, and I’m around to answer any questions that you might have.
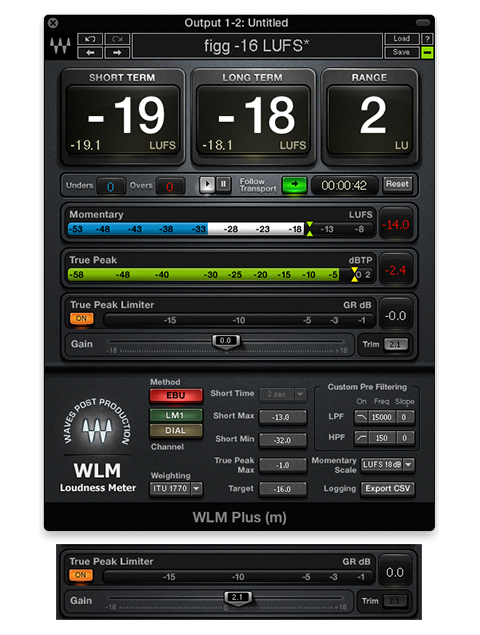
Waves has just released a stellar update to their critically acclaimed WLM Loudness Meter. The new WLM Plus version, available for free to those who are eligible – includes a few new and very useful features.
The plugin now acts as both a Loudness Meter and a Loudness Processor. New controls (Gain/Trim) are located in the Processing Panel and are designed to apply loudness normalization and correction. There is also a new switchable True Peak Limiter that adheres to the True Peak parameter defined in the selected running preset.
Here’s how it works:
Notice below I am running WLM Plus using my own custom preset (figg -16 LUFS). Besides the obvious Integrated Loudness target (-16 LUFS), I’ve defined -1.0 dBTP as my True Peak ceiling.
What you need to do is insert the plugin at the end of your chain. Turn on the True Peak Limiter. Now play through the entire segment that you wish to measure and correct. During playback the textField value located on the WLM Plus Trim button will update in realtime, displaying the proper amount of gain compensation that is necessary to meet the Integrated Loudness target (it’s +2.1 dB in this example).
When measurement is complete, simply press the Trim button. This will set the Gain slider to the proper value for accurate compensation. Finish up by bouncing the segment through WLM Plus, much the same as any processing plugin. The processed audio will now match the Integrated Loudness Preset target and True Peaks will be limited accordingly.
I haven’t tested this in Pro Tools but my guess is this also works when using WLM Plus as an Audio Suite process on individual clips.
Of course you can make a manual adjustment to the Gain slider as well. In this case you would use the displayed Trim Value to properly set the necessary amount of gain compensation.
Great update to this well designed Loudness Meter.
With the release of the Adobe “CC” versions of Audition and Premiere Pro, users now have access to a customized version of the tc electronic Loudness Radar Meter.
In this video from NAB 2013, an attendee asks an Adobe Rep: “So I’ve heard about Loudness Radar … but I don’t really understand how it works.”
I thought it would be a good idea to discuss the basics of Loudness Radar, targeting those who may not be too familiar with it’s design and function. Before doing so, there are a few key elements of loudness meters and measurement that must be understood before using Loudness Radar proficiently.
Loudness Measurement Specifications:
Program “Integrated” Loudness (I): The measured average loudness of an entire segment of audio.
Loudness Range (LRA): The difference between average soft and average loud parts of a segment.
True Peak (dBTP): The maximum electrical amplitude with focus on intersample peaks.
Meter Time Scales:
• Momentary (M) – time window:400ms
• Short Term (S) – time window:3sec.
• Integrated (I) – start to stop
Program Loudness Scales
Program Loudness is displayed in LUFS (Loudness Units Relative to Full Scale), or LKFS (Loudness K-Weighted Relative To Full Scale). Both are exactly the same and reference an Absolute Scale. The corresponding Relative Scale is displayed in LU’s (Loudness Units). 0 LU will equal the LUFS/LKFS Loudness Target. For more information please refer to this post.
LU’s can also be used to describe the difference in Program Loudness between two segments. For example: “My program is +3 LU louder than yours.” Note that 1 LU = 1 dB.
Meter Ranges (Mode/Scale)
Two examples of this would be EBU +9 and EBU +18. They refer to EBU R128 Meter Specifications. The stated number for each scale can be viewed as the amount of displayed loudness units that exceed the meter’s Loudness Target.
From the EBU R128 Doc:
1. (Range) -18.0 LU to +9.0 LU (-41.0 LUFS to -14.0 LUFS), named “EBU +9 scale”
2. (Range) -36.0 LU to +18.0 LU (-59.0 LUFS to -5.0 LUFS), named “EBU +18 scale”
The EBU +9 Range is well suited for broadcast and spoken word. EBU +18 works well for music, film, and cinema.
Loudness Compliance: Standardized vs. Custom
As you probably know two ubiquitous Loudness Compliance Standards are EBU R128 and ATSC A/85. In short, the Target Loudness for R128 is -23.0 LUFS with peaks not exceeding -1.0 dBTP. For ATSC A/85 it’s -24.0 LKFS, -2.0 dBTP. Compliant loudness meters include presets for these standards.
Setting up a loudness meter with a custom Loudness Target and True Peak is often supported. For example I advocate -16.0 LUFS, -1.5 dBTP for audio distributed on the internet. This is +7 or 8 LU hotter than the R128 and/or ATSC A/85 guidelines (refer to this document). Loudness Radar supports full customization options to suit your needs.
Pause/Reset
Loudness meters have “On and Off” switches, as well as a Reset function. For Loudness Radar – the Pause button temporarily halts metering and measurement. Reset clears all measurements and sets the radar needle back to the 12 o’clock position. Adobe Loudness Radar is mapped to the play/pause transport control of the host application.
Gating
The Loudness Standard options available in the Loudness Radar Settings designate Measurement Gating. In general, the Gate pauses the loudness measurement when a signal drops below a predefined threshold, thus allowing only prominent foreground sounds to be measured. This results in an accurate representation of Program Loudness. For EBU R128 the relative threshold is -10 LU below ungated LUFS. Momentary and Short Term measurements are not gated.
• ITU BS.1770-2 (G10) implements a Relative Gate at -10 LU and a low level Gate at -70 LU.
• Leq(K) implements a -70 LU low level Gate to avoid metering bias during 100% silent passages. This setting is part of the ATSC A/85 Specification.
In Audition CC you will find Loudness Radar located in Effects/Special/Loudness Radar Meter. It is also available in the Effects Rack and in the Audio Mixer as an Insert. Likewise it is available in Premiere Pro CC as an Insert in the Audio Track Mixer and in the Audio Effects Panel. In both host applications Loudness Radar can be used to measure individual clips or an entire mix/submix. Please note when measuring an audio mix – Loudness Radar must be placed at the very end of the processing chain. This includes routing your mix to a Bus in a multitrack project.
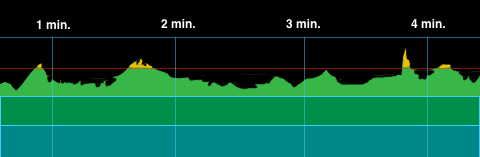
Most loudness meters use a horizontal graph to display Short Term Loudness over time. In the image below we are simulating 4 minutes of audio output. The red horizontal line is the Loudness Target. Since the simulated audio used in this example was not very dynamic, the playback loudness is fairly consistent relative to the Loudness Target. Program Loudness that exceeds the Loudness Target is displayed in yellow. Low level audio is represented in blue.
Each horizontal colored row represents 6 LU of audio output. This is the meter’s resolution.
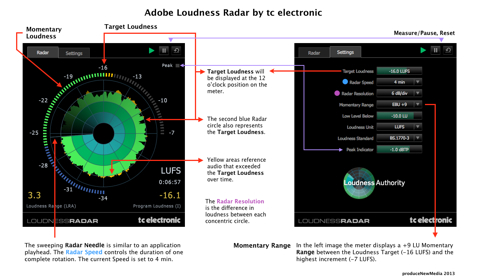
Loudness Radar (click image below for high-res view) uses a circular graphic to display Short Term Loudness. A rotating needle, similar to a playhead tracks the audio output at a user defined speed anywhere from 1 minute to 24 hours for one complete rotation.
The circular LED meter on the perimeter of the Radar displays Momentary Loudness, with the user defined Loudness Target (or specification target) visible at the 12 o’clock position. The Momentary Range of the LED meter reflects what is selected in the Settings popup. The user can also customize the shift between green and blue colors by adjusting the Low Level Below setting.
The numerical displays for Program Loudness and Loudness Range will update in real time when metering is active. The meter’s Loudness Unit may be displayed as LUFS, LFKS, or LU. The Time display below the Loudness Unit display represents how long the meter is/was performing an active measurement (time since reset). Lastly the Peak Indicator LED will flash when audio peaks exceed the Peak Indicator setting.
If this is your first attempt to measure audio loudness using a loudness meter, focus on the main aspects of measurement:Program, Short Term, and Momentary Loudness. Also, pay close attention to the possible occurrence of True Peak overs.
In most cases the EBU R128 and ATSC A/85 presets will be suitable for the vast majority of producers. Setup is pretty straightforward:select the standardization preset that displays your preferred Loudness Unit (LUFS, LKFS, or LU’s) and fire away. My guess is you will find Loudness Radar offers clear and concise loudness measurements with very little fuss.
Notes:
You may have noticed the Loudness Target used in the above graphic is -16.0 LUFS. This is a custom target that I use in my studio for internet audio loudness measurements.
Wide variations in average (Program/Integrated) Loudness are common across all forms of audio distributed on the internet. This includes audio Podcasts, Videocasts, and Streaming Media. This is due to the total lack of any standardized guidelines in the space. Need proof? Head over to Twit.tv and listen to a few minutes of any one of their programs. Use headphones, and set your playback volume to a comfortable level.
Now head over to PodcastAnswerMan.com, and without making any change to your playback volume – listen to the latest program.
I rest my case.
In fact, there is a 10 LU difference in average loudness between the two. Twit.tv programs check in at approximately -22 LUFS. PodcastAnswerMan checks in at approximately -12 LUFS. I find this astonishing, but I am not surprised. I’m not signaling them out for any lack of quality issues or anything like that. In my view both networks do a great job, and my guess is they have sizable audiences. Both shows are well produced and it simply makes sense to compare them in this case study.
With all this in mind let me stress that at this particular time I am not going to focus on discussing Program Loudness variations or any potential suggested standard. I can assure you this is coming! I will say that I advocate -16.0 LUFS (Program/Integrated Loudness) for all media formats distributed on the internet. Stay tuned for more on this. For now I would like to discuss True Peak compliance that will be a vital part of any recommended distribution standard.
What surprises me more than Program Loudness inconsistency is just how many producers are pushing files with clipped, distorted audio. In many cases Intersample Peaks are present in audio files that have been normalized to 0 dBFS. (For more information on Intersample Peaks please refer to this brief explanation). Producers need to correct this problem before their audio is distributed.
The Tools
One of the most useful features included in Adobe Audition is the Match Volume Processor. This tool includes various options that allow the operator to “dial in” specific average loudness and peak amplitude targets. After processing, the operator can examine the results by using Audition’s Amplitude Statistics analysis to check for accuracy.
Notice in the snapshot above I set the processor to Match To: Total RMS, with a -18.50 dB RMS average target. I’ve also selected the Use Limiting option. I’m able to dial in custom Look-Ahead and Release Time parameters as I see fit. Is there something missing? Indeed there is. Any time you push average levels you run the risk of clipping the source. In Audition the Match Volume/Use Limiting option lacks the capability for the operator to set a specific Peak Amplitude Ceiling. I’ve determined that in certain situations Peak Amplitudes reach a -0.1 dB ceiling resulting in possible clipped samples and True Peak levels that exceeded 0dBFS. Keep in mind this is not always the case. The results depend on the Dynamic Range and available Headroom of any source.
So how do we handle it?
Notice above the Match Volume Processor offers two Peak Amplitude options: Peak Amplitude and True Peak Amplitude. The European Broadcasting Union’s EBU R128 spec. dictates -1.0 dBTP (True Peak) as the ultimate ceiling to meet compliance. Here in the states ATSC A/85 dictates -2.0 dBTP. Since most, if not all audio formats distributed on the internet are delivered in lossy formats, it is important to pay close attention to True Peak Amplitude for both source (lossless) and distribution (lossy) files.
I advocate -1.0 dBTP as the standard for internet based audio file delivery. True Peak Limiters are able to detect and alleviate the possibility of Intersample Peaks from occurring. It is recommended to pass audio through a True Peak compliant limiter after loudness normalization and prior to lossy encoding. Options include ISL by Nugen Audio, Elixir by Flux, and (the best kept secret out there) TB Barricade by ToneBoosters. If you are running Audition, Match To: True Peak Amplitude and you should be all set.
The plugin developers mentioned above as well as Waves, MeterPlugs, tc electronic, Grimm Audio, and iZotope supply Loudness Meters and toolsets that display all aspects of loudness specifications including True Peak alerts. Visit this page for a list of supported Loudness Meters.
If True Peak detection and compliance is not within your reach due to the lack of capable tools, a slightly more aggressive ceiling (-1.5 dBFS) is recommended for Peak Normalization. The additional .5 dB acts as a sort of safety net, insuring maximum peak amplitude remains at or below -1.0 dBFS. One thing to keep in mind … performing Peak Amplitude Normalization after Loudness Normalization may very well result in a reduction in average, program loudness. Once again changes to the processed audio will depend on the audio attributes prior to Peak Normalizing.
Below I’ve supplied data that supports what I noted above. The table displays three iterations of a test file: Input, Loudness Normalized Intermediate, and final Output. For this test I used the ITU-R BS.1770-2 “Match To” option in Audition’s Match Volume Processor. I pushed the average target to -16.0 LUFS. As noted, this is the target that I advocate for internet and/or mobile audio. This target is +7 LU hotter than R128 and +8 LU hotter than ATSC A/85.
After processing the Input file, the average target was met in the Intermediate file, but True Peak overs occurred. The Intermediate file was then passed through a compliant True Peak Limiter with it’s ceiling set to -1.0 dBTP. Compliance was met in the Output with a minimal reduction in Program Loudness.
Producers: there is absolutely no excuse if your audio contains distortion due to clipping! At the very least you should Peak Normalize to -1.5 dBFS prior to encoding your lossy MP3. Every audio application on the planet offers the option to Peak Normalize, including GarageBand and Audacity. Best case scenario is to adopt True Peak compliance and learn how to use the tools that are necessary to get it done. If you are an experienced producer or professional, and you come across content that does not comply – reach out and offer guidance.
Back in October of 2012 I wrote about my purchase and initial impression of MaxxVolume by Waves. Let me first say I’m so glad I bought this tool. Secondly, my timing was impeccable. I was under the impression (when I purchased it) that the price of this plugin was significantly reduced on a permanent basis from $400 to $149 for the “Native” single version. Not the case. It is currently selling for $350 and discounted to $320. Like I said – my timing was impeccable.
Anyway, I’ve spent many hours working with this tool. Before I discuss one instance of my workflow, let me also mention that I recently purchased a license for their Renaissance VoxDynamics Processor. This is yet another stellar tool by Waves. It features three slider “faders”: Gate, Compressor, and Gain. The Gate (Downward Expander) is very impressive. It works well when it may be necessary to tame an elevated noise floor in something like a voice over. The Compression algorithm is what really makes this plugin shine. As expected this setting controls the amount of Dynamic Range Compression applied to the source. At the same time it applies automatic makeup gain. What’s special is as the output gain potentially increases, the plugin will automatically prevent clipping by applying peak limiting. It’s all handled by a single slider setting. It turns out the High Level Compressor included in MaxxVolume is similar to the Compression stage in Renaissance Vox …
I’ve settled in on an order in which I set up MaxxVolume to act as a leveler when processing spoken word. I load the plugin with all controls in the OFF state. First I turn on the Low Level Compressor. This is essentially an Upward Expander that increases the level of softer passages. It doesn’t take much of an increase in gain to achieve acceptable results. At this point I rely solely on my ears for the desired effect.
Next I turn on the Gate (Downward Expander) and listen for any problems with the noise floor that may have resulted from the gain I picked up with the Low Level Compressor. Since I pass all my files through iZotope RX2 before introducing them to MaxxVolume – they are pretty quiet. In most cases the Gate’s Threshold is set somewhere between -60 and -70 dB. By the way the processor is set to the LOUD mode. This setting uses a more aggressive release resulting in a slightly “louder” output signal.
Now that I’ve dealt with low level signals and any potential noise floor issues – I set the Global Gain to -1.0dB. If I am dealing with a previously (loudness) normalized file with a set average target, I almost never deviate from this -1.0dB setting.
The last stage of the processor setup affects the aggression of the Leveler and handles Dynamic Range Compression. As previously stated – the High Level Compressor also applies automatic makeup gain as it’s Threshold is decreased. What’s interesting is it also applies gain compensation to the signal where aggressive leveling may result in heavy attenuation. Here once again if I am dealing with a segment with a set average loudness target, I need to maintain it. So I turn on the Leveler and set it’s Threshold to apply the desired amount of leveling. When the audio passes (goes above) the threshold, leveling is active. The main Energy Meter displays the audio level after the leveler and before any additional dynamics processing functions.
I finish up by turning on the High Level Compressor, setting it’s Threshold to apply the necessary amount of gain compensation to maintain my average (Program/Integrated) Loudness target. I use Nugen’s VisLM Loudness Meter to monitor loudness. Finally I fine tune the Low Level Compressor and Gate.
This particular workflow is just one example of how I use MaxxVolume. The processor does an excellent job when setup to function as a speech volume leveler. In other instances I use it to attenuate playback of audio segments, programs, etc. that have been normalized to a much higher average loudness target than I see fit. With the proper settings MaxxVolume provides a highly customized method of gain attenuation that sounds so much better than just reducing output levels with channel faders in a DAW.
MaxxVolume is now an indispensable tool in my audio processing kit …
One of the great features of Final Cut Pro X is the availability of Apple’s 64bit Logic audio processing plugins (aka Filters). In fact FCPX supports all 64bit Audio Units developed by third parties.
Let me first point out I’ve tested a fair amount of 64bit Audio Units in FCPX. Results have been mixed. Some work flawlessly. A few result in sluggish performance. Others totally crash the application. I can report that Nugen’sISL True-Peak Limiter and Wave ArtsFinal Plug work very well in the FCPX environment.
ISL is a Broadcast Compliant True-Peak Limiter that uses standardized ITU-R B.S 1770 algorithms. Settings include Input Gain and True-Peak Limit. ISL fully supports Inter-Sample Peak detection.
Final Plug allows the operator to set a limiting Threshold as well as a Peak Ceiling. Decreasing the Threshold will result in an increase of average loudness without the audio output ever exceeding the Ceiling.
Recently Flux released a 64bit version of Elixir, their ITU/EBU compliant True-Peak Peak Limiter. Currently (at least on my MacPro) the plugin is not usable. Applying Elixir to a clip located in the FCPX storyline causes an immediate crash. I’ve reported this to the developer and have yet to hear back from them.
The plugins noted above range in price from $149 to $249.
One recommendation that often appears on discussion forums and blogs is the use of the Logic AU Peak Limiter to boost audio loudness while maintaining brick-wall limiting. This process is especially important when a distribution outlet or broadcast facility defines a specific submission target. A few audio pro’s have taken this a step further and recommended the use of the Logic Compressor instead of the Peak Limiter. In my view both are good. However proper setup can be daunting, especially for the novice user.
These days picture editors need to know how to color correct, create effects, and handle various aspects of audio processing. If you are looking for a straight forward audio tool that will brick-wall limit and (if necessary) maximize loudness, I think I found a viable solution.
LoudMax is an easy to use Peak Limiter and Loudness Maximizer. Operators can use this plugin to drive audio levels and to set a brick-wall Output Ceiling.
The LoudMax Output Slider sets the output Ceiling. So if you are operating in the “just to be safe mode”, or if you need to limit output based on a target spec., set this accordingly. If you need to increase the average loudness of a clip – decrease the Threshold setting until you reach the desired level. The Output Ceiling will remain intact.
LoudMax also includes a useful Gain Reduction Meter. If viewing this meter is not important to you – there’s no need to run the plugin GUI. The Threshold and Output parameters are available as sliders, much the same as any other FCPX Filter or Template. You can also set parameter Keyframes and save slider settings as Presets.
Using the Logic Peak Limiter and/or Compressor is definitely a viable option. Keep in mind that achieving acceptable results takes practice. Proper usage does require a bit more ingenuity due to the complexity of the settings. I’ll be addressing the concepts of audio dynamics Compression in the future. For now I urge you to take a look at LoudMax. It’s 32/64bit and available in both VST and AU formats. The AU Version works fine in FCPX. I found the processed audio results to be perfectly acceptable.
At the time of this writing LoudMax is available as Freeware.
If you look in the FCPX Titles Effects Browser under the Lower Thirds Category you will notice an Information Bar Lower Thirds. The is a bundled FCPX Title. The title itself is actually quite stylish. It’s subtle, with a semitransparent black bar and customizable text positioned on two lines.
A few days ago I was sifting through a forum and noticed a post by a member who uses this title regularly. He was asking for help regarding the opacity of the “bar.” Basically it’s opacity was not customizable. It was preset to somewhere around 50%. The forum member politely asked if someone could possibly load up the title in Motion, tweak in an Opacity slider for the bar, and make it available. I knew this would be easy, especially if the default Title supported the “Open a copy in Motion” option. It did and the rest is history.
If you review the settings snapshot below you will notice I added additional options that make my version much more useful, at least for me. I added support for Global Y Positioning (more on this below), Fade In/Out Frames, Bar Opacity, Bar Left Indent, and Bar Roundness.
By default the Title places the text within the 1.78:1 Title Safe Area located at the bottom left of the zone. The Global Y Position setting allows the operator to cumulatively move all Title elements up on the Y axis to 2.35:1 Title Safe positioning.
The Original version of the Title has two check boxes that control whether all elements fade in and/or out. I added Fade in and Fade Out sliders that support frame by frame customization. Setting the sliders to zero results in no fading.
Bar Opacity is now supported. I believe I set this up to default to 50% Opacity. Regardless – it’s now fully customizable.
Bar Left Indent is an interesting setting. Notice there is also a Bar Roundness setting that will change the shape of the bar. Since by default the bar is anchored to the left of the image frame, applying roundness to it results in a partially obstructed left edge. The Bar Left Indent setting moves the bar’s left edge in a few pixels to the right to compensate. In fact It can be used without any roundness applied as well for creative purposes.
There have been some reports of font change instability. In fact this behavior is also present in the original version of the Title. I found this to be not that big of a deal.
The Installer will place the Title in the FCPX Titles Browser under the Custom Lower Thirds Category/Information Bar Theme.
The latest addition to my audio processing toolset is MaxxVolume by Waves. This dynamics processor has been on my radar for the past few years. I was always under the impression that Waves plugins required an iLok account/key. It was for this reason I never bothered to pull down the demo and test it.
A few days ago I noticed that a few online plugin resellers were advertising a price drop for MaxxVolume. I believe the original price was $300. Sweetwater and DontCrack are currently selling it for $149. I decided to purchase a license. By the way prior to doing so – I realized Waves has moved away from the iLok requirement. They now provide a standalone “Waves License Center” (WLC) application that can be used to manage both purchased and demo licenses. Licenses can be transferred to a host machine and/or a standard (FAT32 formatted) USB Flash Drive. You can then move and manage licenses via the Flash Drive or within their proprietary License Cloud.
After making a purchase you simply register the new product on the Waves site, run WLC, login to your Waves account – and move your license(s) from the cloud to your target destination. I must say the process was easy and seamless.
So what is MaxxVolume? The plugin is a four module dynamics processor: Low Level Compressor, Gate, Leveler, and High Level Compressor. All four processing stages run in parallel.
The Low Level Compressor is essentially an expander. So any signal that falls below the set threshold gets compressed upward. It’s controlled by a Threshold fader and Gain fader. The Gate feature is controlled by a single Threshold fader that applies gentile downward expansion affecting any signal that drops below the threshold setting. The Leveler is essentially an AGC (Automatic Gain Control) controlled by a single Threshold fader. Lastly the High Level Compressor is controlled by a Threshold fader and a Gain fader. This compressor functions just like any standard compressor – when the input signal exceeds the threshold it is attenuated. The Gain setting compensates for the attenuated signal.
Waves notes “It’s a Broadcast tool, bringing any program to a fixed destination level; ideal for radio and TV, podcasting, internet streaming, and more.” It took me some time to get a feel for how the four processing stages interact. So far I like what I’m hearing. The AGC is pretty impressive. I’m using Adobe Audition CS6 as my host. The processor works fine in the Adobe environment.
I will say this tool is not your sort of cut and dry loudness maximizer. It may not be suitable for less advanced or novice users. In my view a clear understanding of upward/downward expansion, AGC, and compression is a necessity.
When preparing to encode MP3 files we need to be aware of the possibility of Intersample Peaks (ISP) that may be introduced in the output, especially when targeting low bit rates. This results from the filtering present in lossy encoding. We alleviate this risk by leaving at least 1 dB of headroom below 0dBFS.
Producers should peak normalize source files slated for MP3 encoding to nothing higher than -1.0 dBFS. In fact I may suggest lowering your ceiling further to -1.5 dBFS sometime in the future. Let me stress that I’m referring to Peak Normalization and not Loudness Normalization. Peak Normalizing to a specific level will limit audio peaks when and if the signal reaches a user defined ceiling. It is possible to set a digital ceiling when performing Loudness Normalization as well. This is a topic for a future blog post.
Notice the ISP in this image lifted from an MP3 wave form. The original source file was peak normalized to -0.1 dBFS and exhibited no signs of clipping.
You can also avoid ISP’s by using a compliant ITU Limiter and setting the ceiling accordingly. During source file encoding this type of limiter will detect when ISP’s may occur in the encoded MP3.
For podcast and internet audio, a limiter set to a standardized ceiling of -1.0/-1.5 dBFS works well and is recommended.
Here’s how it works: we are transferring 24p to 60i, which means we are converting 24 frames per second into 60 fields per second. The first frame of film is transferred to the first two fields of video and the next frame of film is transferred to the next three fields – 2:3. This results in some frames of film spanning two different frames of video or, to put it another way, some frames of video that are composed of fields from two different frames of film.
Here is a glimpse of what I have planned for the next release for aspectRatio:
At this point I’ve implemented a suggested dimensions method that displays values evenly divisible by 16. The results are triggered by the Target Width and returned Output Height calculation.
Select MPEG formats are based on 16×16 macro-blocks. Evenly divisible (by 16) output dimensions will maximize the efficiency of the encoder and yield optimum results. For example: a purist would prefer a small 16:9 distribution video to be 480×272 instead of the common 480×270
Also included in this release: a user defined output font color preference setting [orange/red], and a Menu option that re-opens the main UI window if the user inadvertently closes it while the application is still running.
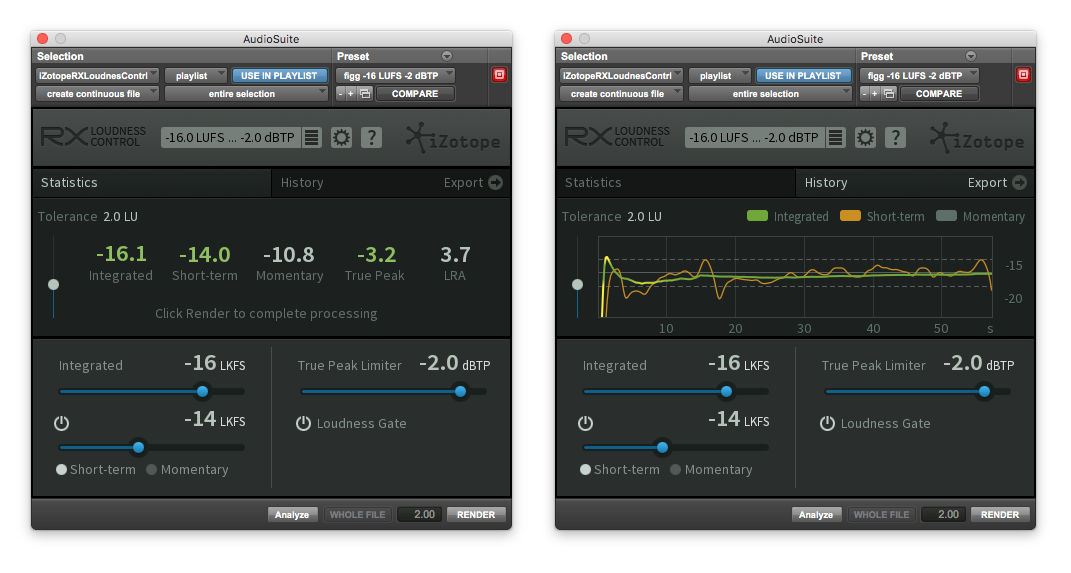
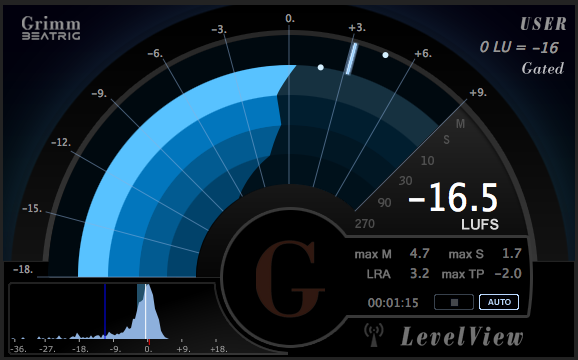
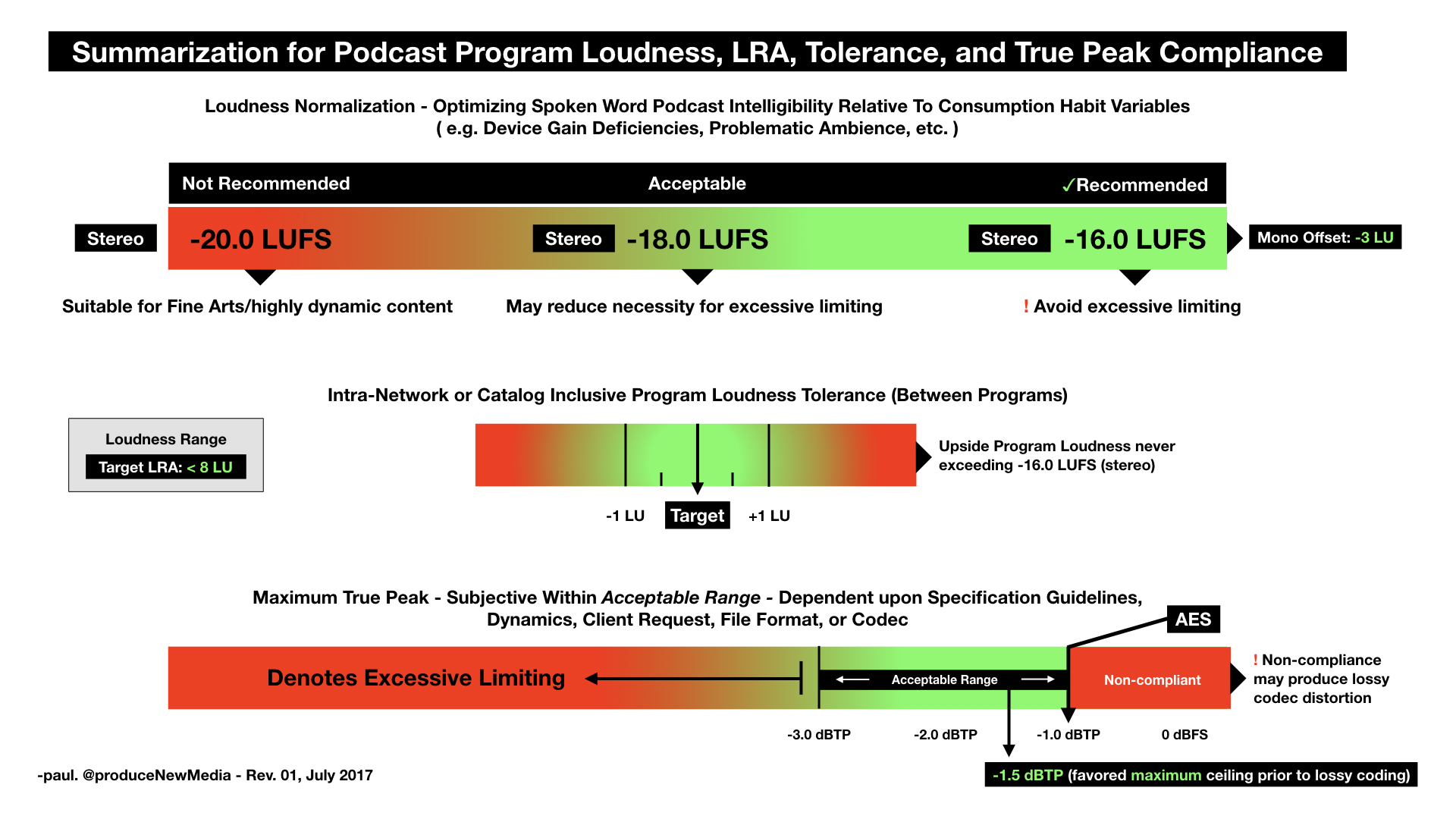


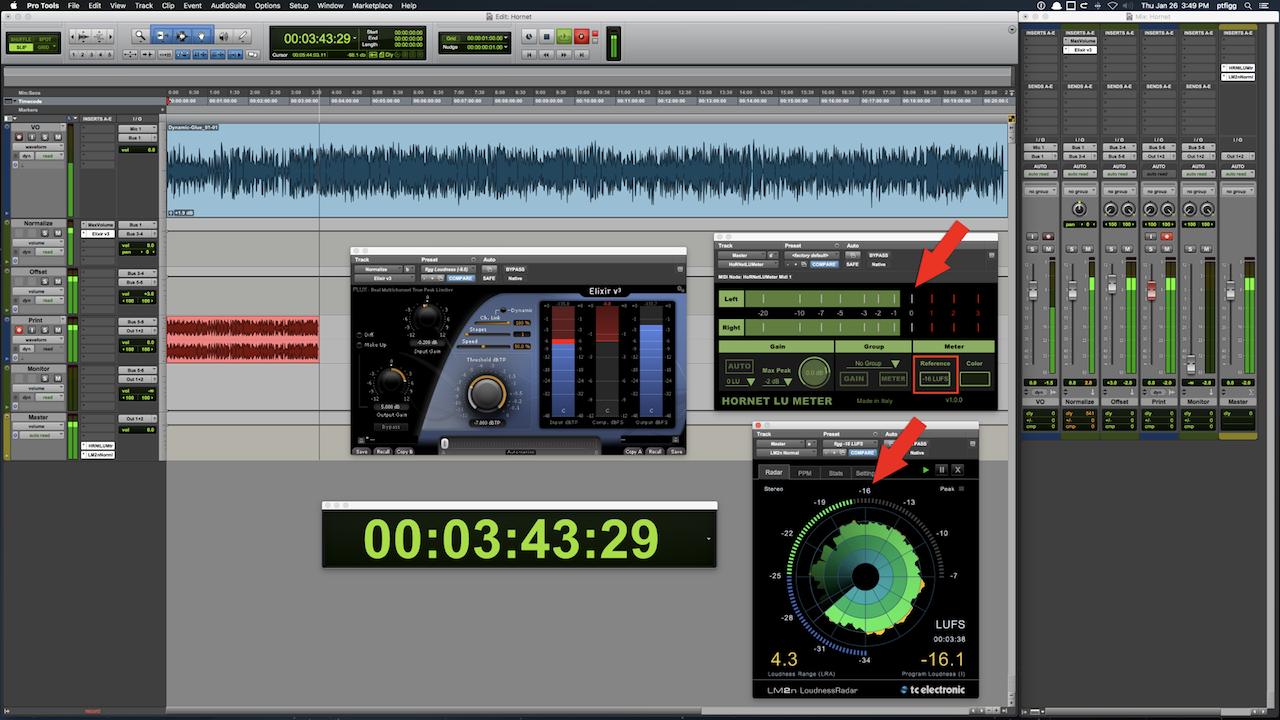
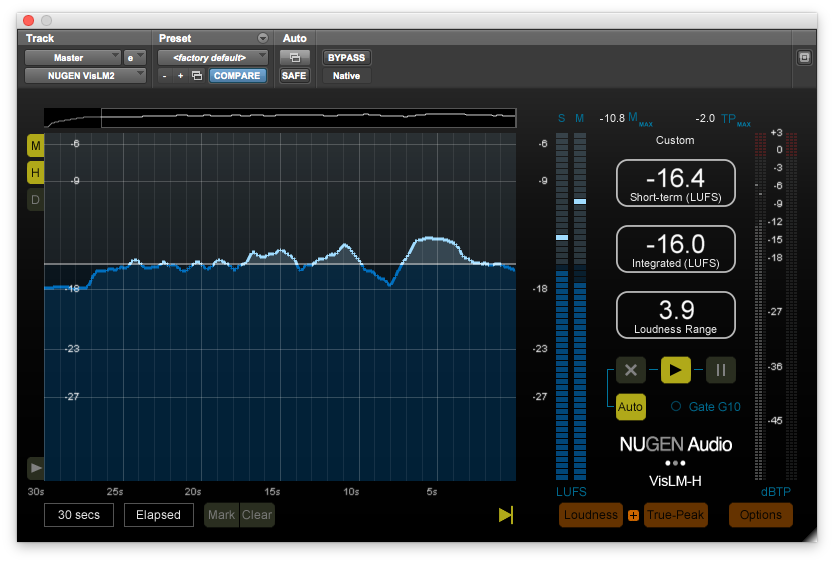

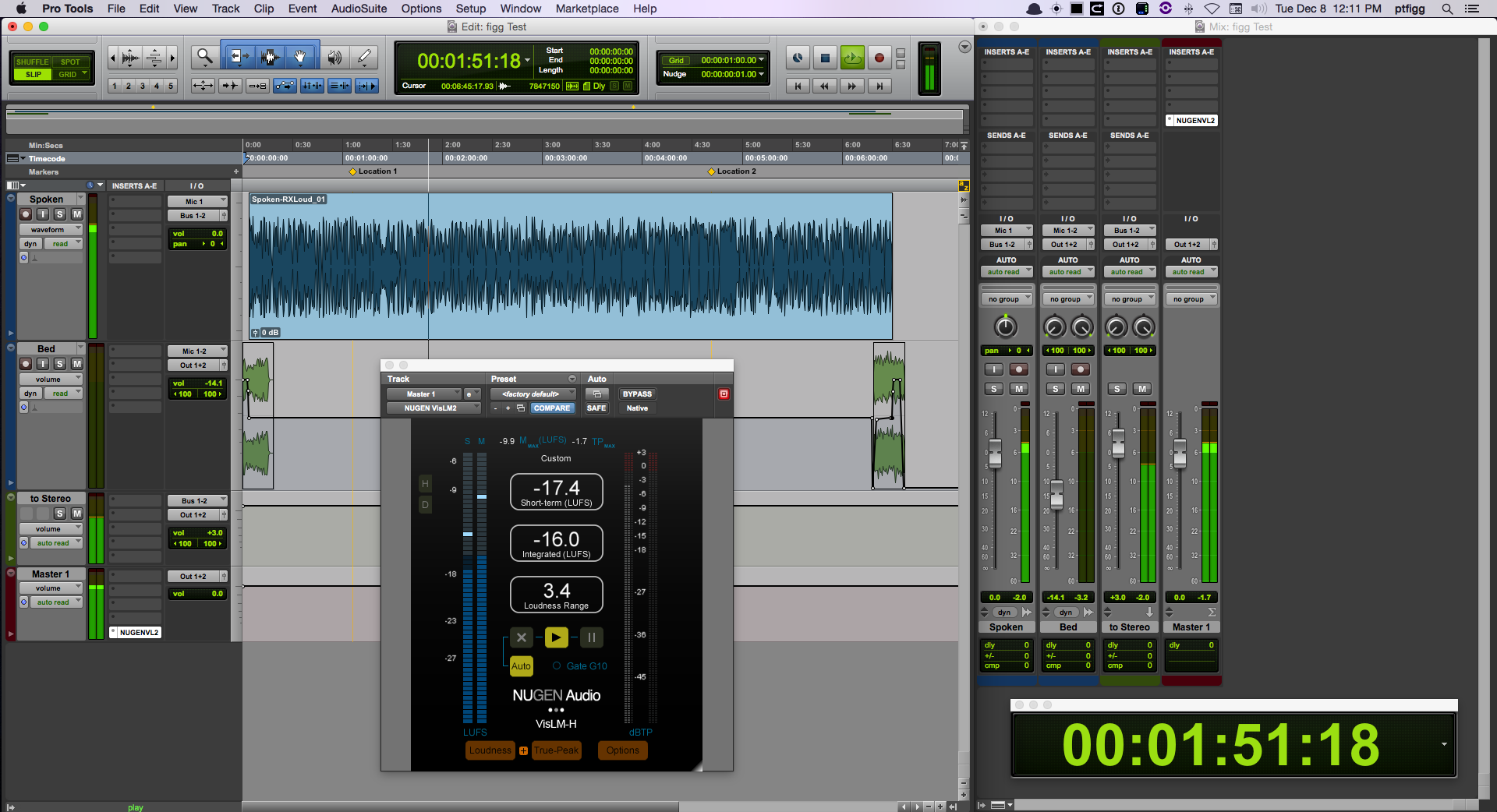
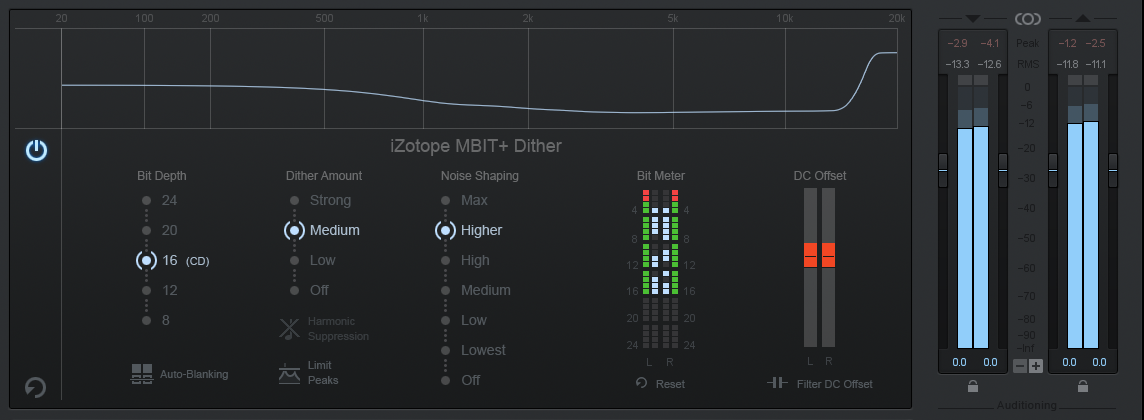
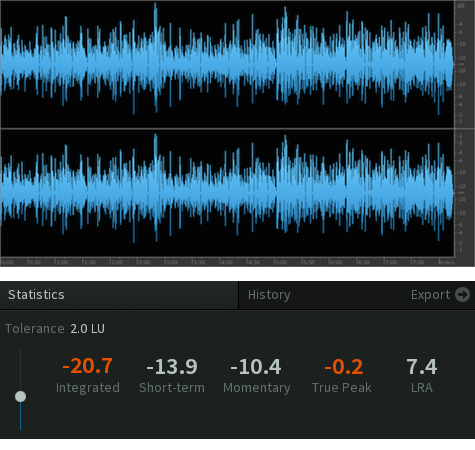
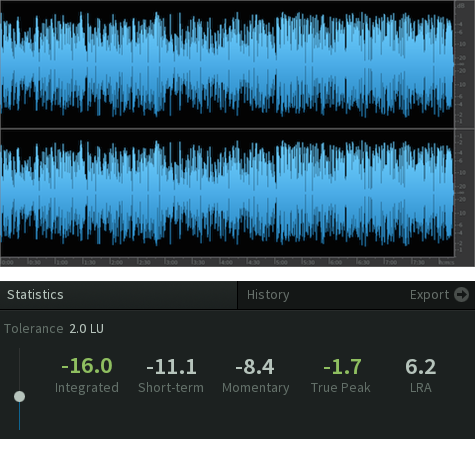



_large.png)