I’d like to share my observations and views on the recently published AES Technical Document AES TD1004.1.15-10 that specifics best practices for Loudness of Audio Streaming and Network File Playback.
The document is a collection of Loudness processing guidelines for diverse platform dependent media streaming and downloading. This would include music, spoken word, and possible high dynamic audio in video streams. The document credits some of the most well respected industry leading professionals, including Bob Katz, Thomas Lund, and Florian Camerer. The term “Podcast” is directly referenced once in the document, where the author(s) state:
“Network file playback is on-demand download of complete programs from the network, such as podcasts.”
I support the purpose of this document, and I understand the stated recommendations will most likely evolve. However in my view the guidelines have the potential to create a fair amount of confusion for producers of spoken word content, mainly Podcast producers. I’m specifically referring to the suggested 4 LU range (-16.0 to -20.0 LUFS) of acceptable Integrated Loudness Targets and the solutions for proper targeting.
Indeed compliance within this range will moderately curtail perceptual loudness disparities across a wide range of programs. However the leniency of this range is what concerns me.
I am all for what I refer to as reasonable deviation or “wiggle room” in regard to Integrated Loudness Target flexibility for Podcasts. However IMHO a -20 LUFS spoken word Podcast approaches the broadcast Loudness Targets that I feel are inadequate for this particular platform. A comparable audio segment with wide dynamics will complicate matters further.
I also question the notion (as stated in the document) of purposely precipitating clipping when adding gain “to handle excessive peaks.”
And there is no mention of the perceptual disparities between Mono and Stereo files Loudness Normalized to the same Integrated Loudness Target. For the record I don’t support mono file distribution. However this file format is prevalent in the space.
Perspective
I feel the document’s perspective is somewhat slanted towards platform dependent music streaming and preservation of musical dynamics. In this category, broad guidelines are for the most part acceptable. This is due to the wide range of production techniques and delivery methods used on a per musical genre basis. Conversely spoken word driven audio is not nearly as artistically diverse. Considering how and where most Podcasts are consumed, intelligibility is imperative. In my view they require much more stringent guidelines.
It’s important to note streaming services and radio stations have the capability to implement global Loudness Normalization. This frees content creators from any compliance responsibilities. All submitted media will be adjusted accordingly (turned up or turned down) in order to meet the intended distribution Target(s). This will result in consistency across the noted platform.
Unfortunately this is not the case in the now ubiquitous Podcasting space. At the time of this writing I am not aware of a single Podcast Network that (A) implements global Loudness Normalization … and/or … (B) specifies a requirement for Integrated Loudness and Maximum True Peak Targets for submitted media.
Currently Podcast Loudness compliance Targets are resolved by each individual producer. This is the root cause of wide perceptual loudness disparities across all programs in the space. In my view suggesting a diverse range of acceptable Targets especially for spoken word may further impede any attempts to establish consistency and standardization.
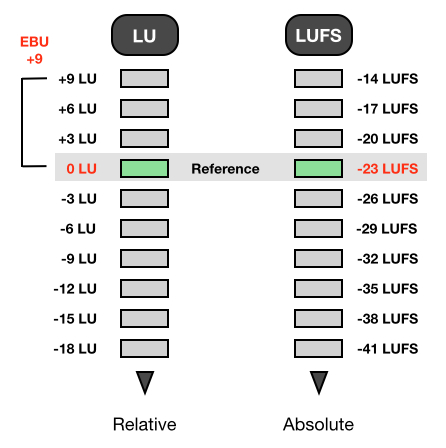
PLR and Retention of Music Dynamics
The document states: “Users may choose a Target Loudness that is lower than the -16.0 LUFS maximum, e.g., -18.0 LUFS, to better suit the dynamic characteristics of the program. The lower Target Loudness helps improve sound quality by permitting the programs to have a higher Peak to Loudness Ratio (PLR) without excessive peak limiting.”
The PLR correlates with headroom and dynamic range. It is the difference between the average Loudness and maximum amplitude. For example a piece of audio Loudness Normalized to -16.0 LUFS with a Maximum True Peak of -1 dBTP reveals a PLR of 15. As the Integrated Loudness Target is lowered, the PLR increases indicating additional headroom and wider dynamics.
In essence low Integrated Loudness Targets will help preserve dynamic range and natural fidelity. This approach is great for music production and streaming, and I support it. However in my view this may not be a viable solution for spoken word distribution, especially considering potential device gain deficiencies and ubiquitous consumption habits carried out in problematic environments. In fact in this particular scenario a moderately reduced dynamic range will improve spoken word intelligibility.
Recommended Processing Options and Limiting
If a piece of audio is measured in it’s entirety and the Integrated Loudness is higher than the intended Target, a subtractive gain offset normalizes the audio. For example if the audio checks in at -18.0 LUFS and you are targeting -20.0 LUFS, we simply subtract 2 dB of gain to meet compliance.
Conversely when the measured Integrated Loudness is lower than the intended Target, Loudness Normalization is much more complex. For example if the audio checks in at -20.0 LUFS, and the Integrated Loudness Target is -16.0 LUFS, a significant amount of gain must be added. In doing so the additional gain may very well cause overshoots, not only above the Maximum True Peak Target, but well above 0dBFS. Inevitably clipping will occur. From my perspective this would clearly indicate the audio needs to be remixed or remastered prior to Loudness Normalization.
Under these circumstances I would be inclined to reestablish headroom by applying dynamic range compression. This approach will certainly curtail the need for aggressive limiting. As stated the reduced dynamic range may also improve spoken word intelligibility. I’m certainly not suggesting aggressive hyper-compression. The amount of dynamic range reduction is of course subjective. Let me also stress this technique may not be suitable for certain types of music.
Additional Document Recommendations and Efficiency
The authors of the document go on to share some very interesting suggestions in regard to effective Loudness Normalization:
1) “If level has to be raised, raise until it reaches Target level or until True Peak reaches 0 dBTP, whichever occurs first. Thus, the sound quality will be preserved, without introducing excessive peak limiting.”
2) “Perform what is noted in example 1, but keep raising the level until the program level reaches Target, and apply either peak limiting or allow some clipping to handle excessive peaks. The advantage is more consistent loudness in the stream, but this is a potential sonic compromise compared to example 1. The best way to retain sound quality and have more consistent loudness is by applying example 1 and implementing a lower Target.”
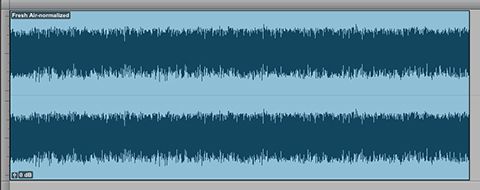
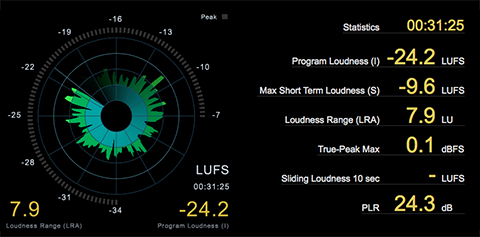
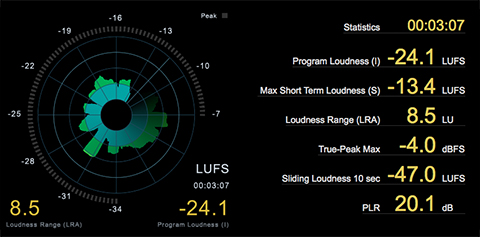
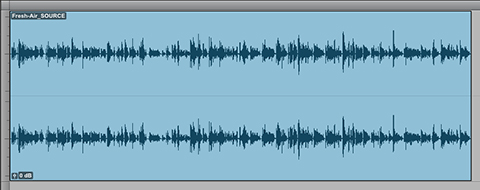
With these points in mind, please review/demo the following spoken word audio segment. In my opinion the audio in it’s current state is not optimized for Podcast distribution. It’s simply too low in terms of perceptual loudness and too dynamic for effective Loudness Normalization, especially if targeting -16.0 LUFS. Due to these attributes suggestion 1 above is clearly not an option. In fact neither is option 2. There is simply no available headroom to effectively add gain without driving the level well above full scale. Peak limiting is unavoidable.
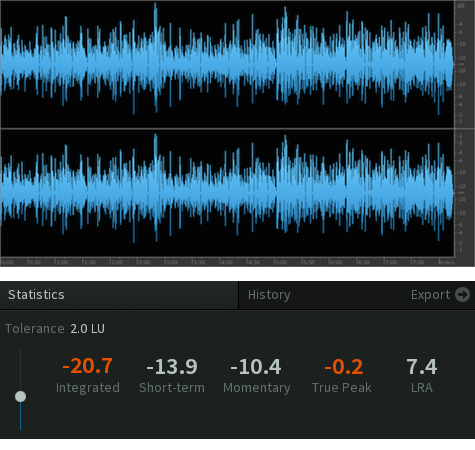
I feel the document suggestions for the segment above are simply not viable, especially in my world where I will continue to recommend -16.0 LUFS as the recommended Target for spoken word Podcasts. Targeting -18.0 LUFS as opposed to -16.0 LUFS is certainly an option. It’s clear peak limiting will still be necessary.
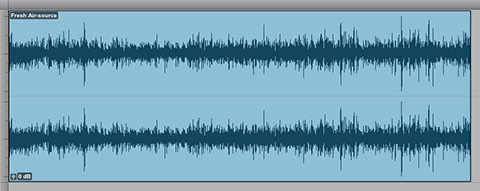
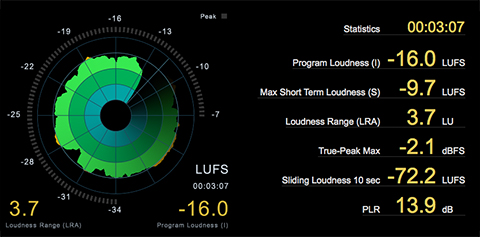
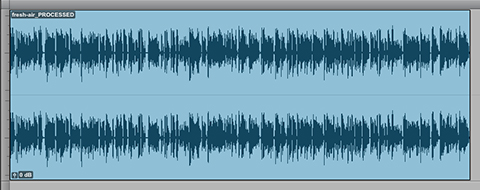
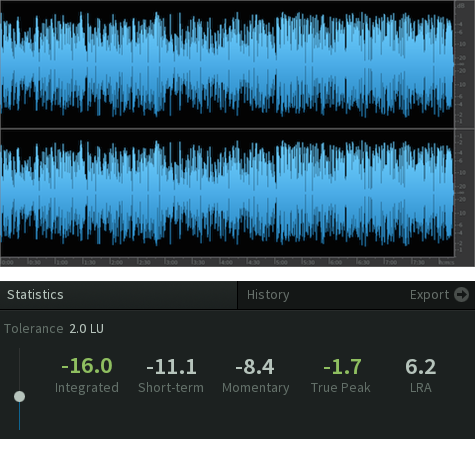
Below is the same audio segment with dynamic range compression applied before Loudness Normalization to -16.0 LUFS. Notice there is no indication of aggressive limiting, even with a Maximum True Peak of -1.7 dBTP.
Regarding peak limiting the referenced document includes a few considerations. For example: “Instead of deciding on 2 dB of peak limiting, a combination of a -1 dBTP peak limiter threshold with an overall attenuation of 1 dB from the previously chosen Target may produce a more desirable result.”
This modification is adequate. However the general concept continues to suggest the acceptance of flexible Targets for spoken word. This may impede perceptual consistency across multiple programs within a given network.
Conclusion
The flexible best practices suggested in the AES document are 100% valid for music producers and diverse distribution platforms. However in my opinion this level of flexibility may not be well suited for spoken word audio processing and distribution.
I’m willing to support the curtailment of heavy peak limiting when attempting to normalize spoken word audio (especially to -16.0 LUFS) by slightly reducing the intended Integrated Loudness Target … but not by much. I will only consider doing so if and when my personal optimization methods prior to normalization yield unsatisfactory results.
My recommendation for Podcast producers would be to continue to target -16.0 LUFS for stereo files and -19.0 LUFS for mono files. If heavy limiting occurs, consider remixing or remastering with reduced dynamics. If optimization is unsuccessful, consider lowering the intended Integrated Loudness Target by no more than 2 LU.
A True Peak Maximum of <= -1.0 dBTP is fine. I will continue to suggest -1.5 dBTP for lossless files prior to lossy encoding. This will help ensure compliance in encoded lossy files. What’s crucial here is a full understanding of how lossy, low bit rate coders will overshoot peaks. This is relevant due to the ubiquitous (and not necessarily recommended) use of 64kbps for mono Podcast audio files.
Let me finish by stating the observations and recommendations expressed in this article reflect my own personal subjective opinions based on 11 years of experience working with spoken word audio distributed on the Internet and Mobile platforms. Please fell free to draw your own conclusions and implement the techniques that work best for you.
-paul.