I was just reading Chris Curran’s Daily Goody segment, published today. The piece is titled Balancing the Levels of All Voices. Chris explains the importance of consistent dialogue levels across multiple participants, and shares various methods to achieve this.
Chris states in his second tip:
>>> “Another way to quickly balance the levels of various participants is to process each participants track to be the same LUFS level. This will make them close to level, but you will always want to adjust the levels slightly using your ears. Because even when the LUFS level of two different voices is the same, the perceived loudness of each voice can differ due to things like proximity to the mic, dynamic range, frequency response of the mic, the timbre of individual voices, etc. So it’s a handy practice to set the LUFS level of each participant to the same value, but then you still have to use your ears.” <<<
Good advise IMHO. Here’s my perspective …
The term LUFS Level is a generalization. It requires clarification.
There are 3 notable measurement descriptors that indicate perceptual Loudness in LUFS/LKFS (or LU’s when using a relative scale):
• Integrated Loudness (also referred to as Program Loudness)
• Short Term Loudness
• Momentary Loudness
Their distinguishing attributes are distinct time and/or averaging intervals: Integrated (cumulative measurement from start to finish), Short Term (3 sec.), and Momentary (400ms). It’s important to recognize the significance of each descriptor.
As well, (and Chris alludes to this in his piece) – you must recognize how a consistent Integrated Loudness measurement across multiple spoken word segments (or session participants) does not necessarily guarantee suitable matched level perception and/or optimized intelligibility.
Remember – Integrated Loudness represents a cumulative measurement from start to finish. For 100% accuracy – the piece must be measured in it’s entirety. Also, the descriptor does not reflect inherent dynamic attributes and/or inconsistencies that my in turn marginalize attempts to optimize perception.
With this in mind, if you choose to use Integrated Loudness as a perceptual Loudness matching indicator – audio optimization (compression, etc.) and target accuracy must be applied and established before relying on any common Integrated Loudness measurement.
What about Short Term/Momentary Loudness?
The 3 sec. averaging interval of the Short Term Loudness descriptor indicates an active, foreground measurement. It is highly useful when analyzing the loudness consistency of spoken word/dialogue. Momentary Loudness will provide even finer “detail” – once again due to it’s inherent averaging interval (400ms).
To summerize: “LUFS Level” is a generalization. As noted there are 3 descriptors (Integrated, Short Term, Momentary). Short Term and Momentary Loudness are useful indicators for the establishment of spoken word consistency. Learn how to use a Loudness Meter (online or offline) to closely monitor each descriptor.
With regards to Loudness Normalization – some processing tools such as RX Loudness Control by iZotope (AAX/Pro Tools only) support user defined Short Term and Momentary Loudness targeting within a certain tolerance range.
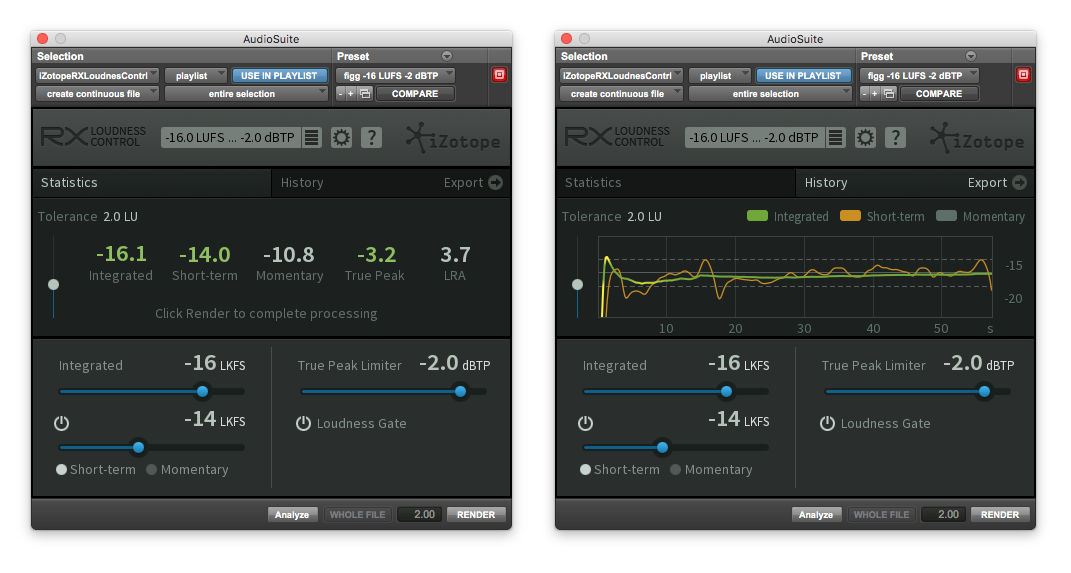
These options, along with the ubiquitous Integrated Loudness definition (and of course subjective audio processing) should provide everything you need in your quest to achieve optimized dialogue.
-paul.