Scores of audio producers in the Podcast Production space have adopted an inaccurate term when referring to basic Loudness Normalization: Loudness Leveling.
First – what is Loudness Normalization? Actually, it’s quite simple:
Audio is measured in it’s entirety. The existing Integrated (Program) Loudness is determined. A gain offset is applied relative to a spec. based or subjective Integrated Loudness target.
For example: if the source audio measures -20 LUFS, and the Loudness Target is -16 LUFS, +4 LU of gain will be applied.
As well, a True Peak Max. Ceiling is defined, which again may be spec. based or subjective. If the required Integrated Loudness gain offset results in overshoots – limiting is applied in order to maintain compliance.
It’s important to note that Loudness Normalization does not correct wide variations in audio levels. As well – it does not guarantee optimized intelligibility for spoken word. If an audio piece (e.g. multiple participant segment) contains inconsistencies as such, the Loudness Normalization gain offset will simply elevate (or reduce) the relative perceptual loudness of the audio. The original dynamic attributes will persist.
That’s it. There’s nothing more to it unless the Loudness Normalization tool features some sort of dynamics optimization process that may or may not be active.
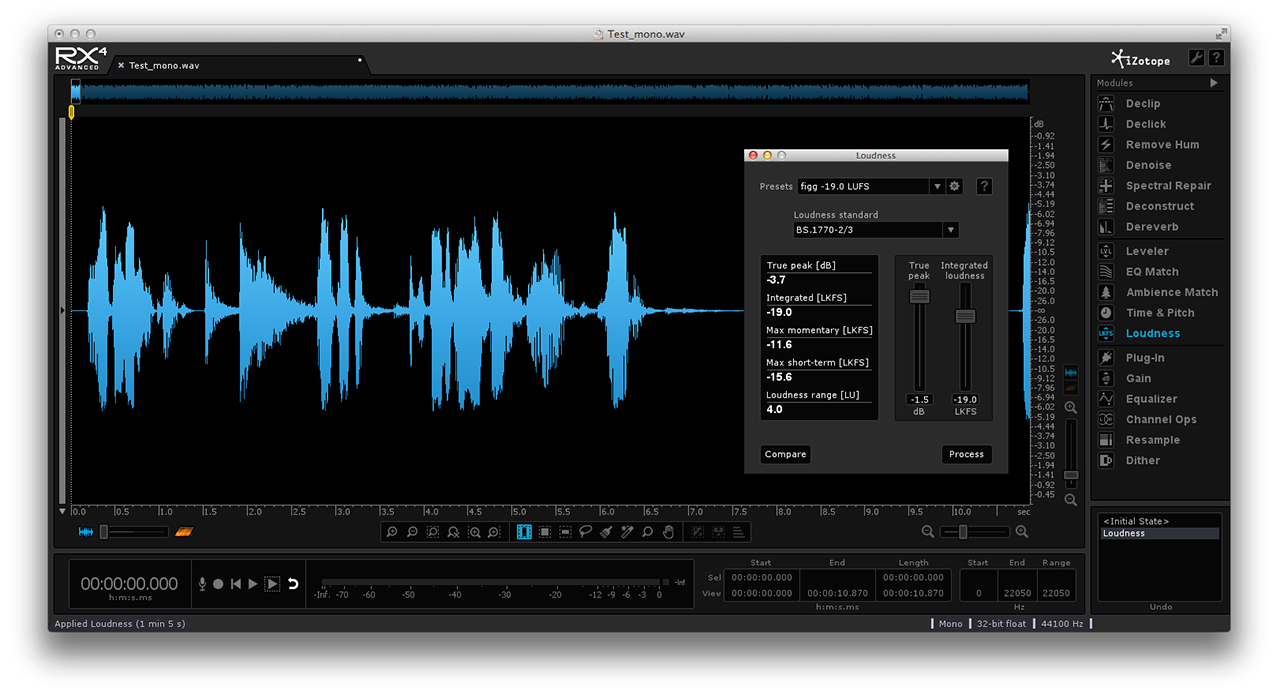
For the record – the Loudness Module included in iZotope’s RX 7 Advanced Audio Editor applies basic Loudness Normalization (measurement, gain, and limiting). It does not apply optimization processing.
Examples
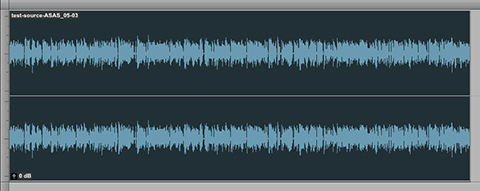
View this source clip waveform. There are two participants with noticeable level inconsistencies:
This is the same clip Loudness Normalized (to -19.0 LUFS). The perceptual loudness is higher. However the level inconsistencies persist:
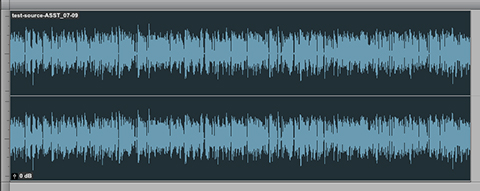
Leveling is a process that addresses and corrects noted inconsistencies and level variations. It is accomplished by the use of gain riding plugins and/or specialty tools that rely on complex algorithms. One basic example is the use of an “RMS” Compressor featuring an optimal and often extended release time parameter.
This is a “leveled” version of the original source clip displayed above. The previously persistent level inconsistencies no longer exist.
Finally, this is the leveled audio, Loudness Normalized to -19.0 LUFS. The described processes were in fact discrete.
I hope I’ve made it clear that the term Loudness Leveling is not an accurate term to describe Loudness Normalization. The key is that Loudness Normalization is gain and limiting. It does not correct inconsistent level variations. You’ll need to implement discrete Leveling processes to address any persistent inconsistencies.
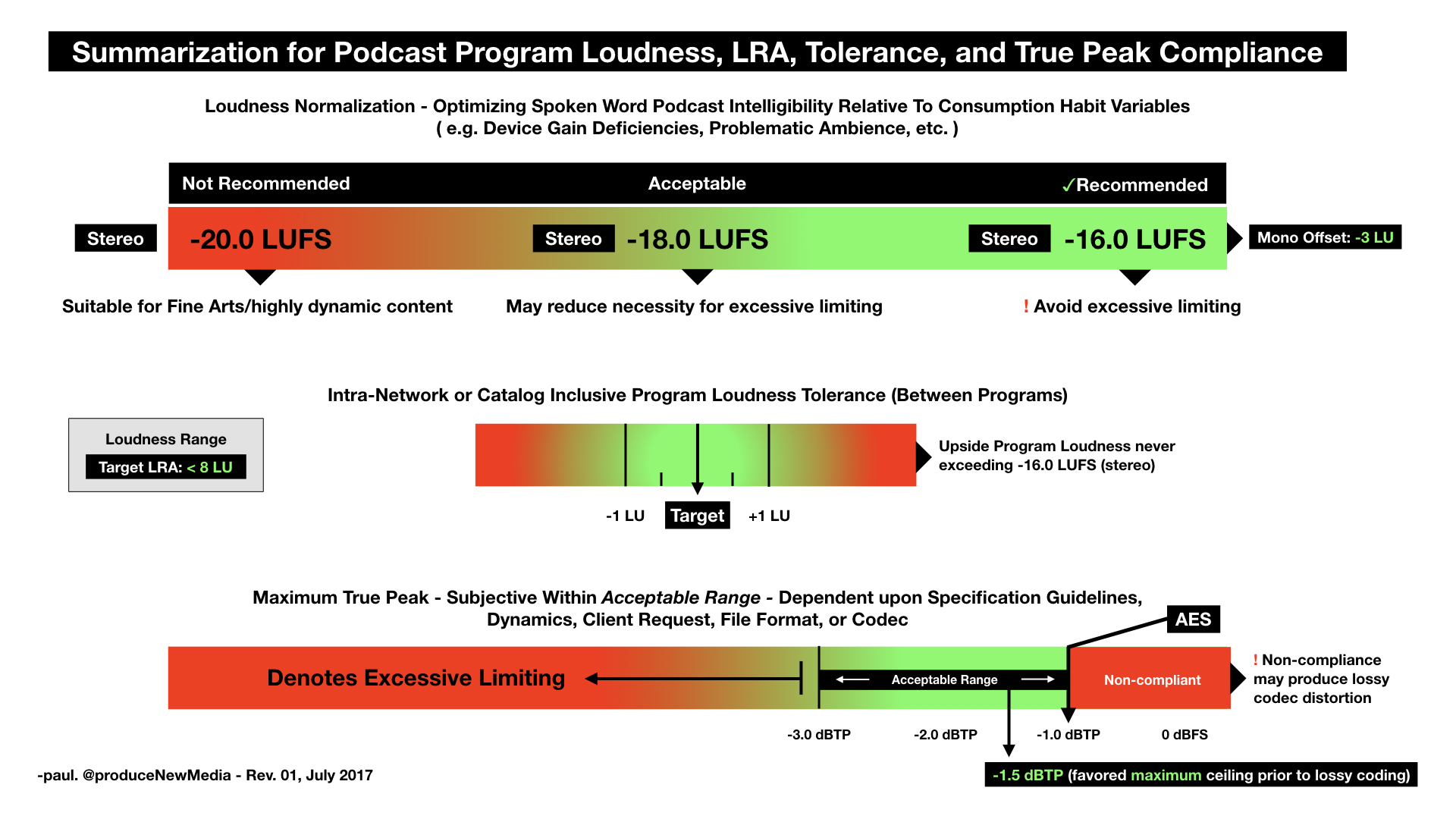
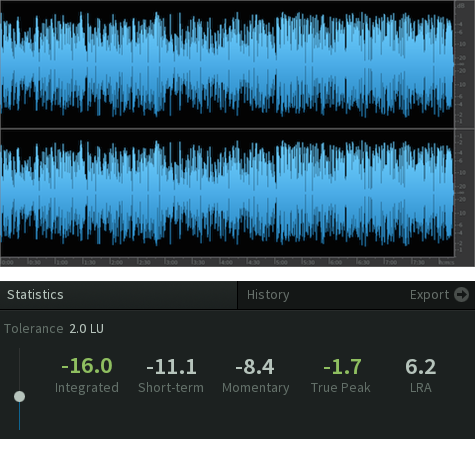
– I continue to endorse -16.0 LUFS for (stereo) Podcast distribution. If meeting this target requires an excessive amount of limiting, a slightly lower target is a viable option. However from my perspective a -20.0 LUFS spoken word piece consumed in a less than ideal environment on a mobile device would be problematic. I’m comfortable supporting upwards of a -2.0 LU deviation from the recommended -16.0 LUFS target (when applicable).
**Note mono files require a -3 LU offset to establish perceptual equivalence to stereo file targets.
– Loudness Range (LRA) is a statistical representation of Loudness distribution and/or the Loudness measurement. An LRA no higher than 8 LU will help optimize intelligibility by restricting dynamics and/or wide variations in Loudness over time.
– Networks and Catalog based program sets managed by indie producers must institute Program Loudness consisctency across all distributed media. This will free listeners from making constant playback volume adjsutments when listening to several programs in succession. Up to 1.0 LU tolerance (+/-) is reasonable. However upside Program Loudness should never exceed -16.0 LUFS.
– Without sufficient headroom – lossy, low bitrate encoding may generate peak levels that exceed a compliance ceiling and/or introduce distortion. -1.5 dBTP is the favored maximum ceiling prior to lossy coding. Of course a lesser value (e.g -2.0 dBTP) is appropriate. However, a peak ceiling below -3.0 dBTP may indicate excessive limiting. This should be avoided.
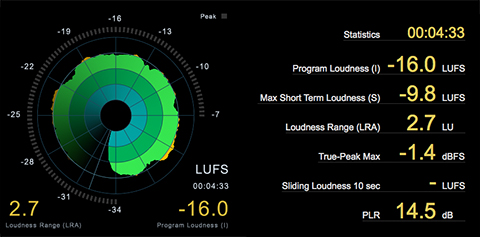
The attached image displays a processing workflow designed to optimize Spoken Word intelligibility. The workflow also demonstrates a realtime example of Integrated Loudness compliance targeting.
There are 7 reference point Sections worth noting:
Section A includes the Adobe Audition Effects Rack Signal Level Meters indicating the source (Input) level and the (Output) level. The Output level reflects the results of the workflow’s inserted plugins. The chain includes a Compressor, a Limiter, and a Loudness Meter. Note the level meters indicate signal level. They do not indicate or represent perceptual Loudness.
Section B displays the gain reduction applied by the Compressor at the current position of the playhead. For the test/source audio I determined an average of 6dB of gain reduction would yield acceptable results. The purpose of this stage is to reduce the dynamic range and/or dynamic structure of the Spoken Word resulting in optimized intelligibility AND to prevent excessive down stream limiting. This is an important workflow element when preparing Spoken Word audio for Internet/Mobile, and Podcast distribution.
Section C includes my subjective limiting parameters. The Limiter will add the required amount of gain to achieve a -16.0 LUFS deliverable while adhering to a -1.5 dBTP (True Peak Max). If the client, platform, or workflow requires an alternative Loudness target and/or Maximum True Peak ceiling – the parameters and their mathematical relationship may be altered for customized targeting. Please note the Maximum True Peak referenced in any spec. is more of a ceiling as opposed to a target. In essence the measured signal level may be lower than the specified maximum.
Section D indicates the amount of limiting that is occurring at the current position of the playhead.
Section E displays the user defined Integrated Loudness target located above the circular Momentary Loudness LED (12 o’clock position). The defined Integrated Loudness target is also visually represented by the Radar’s second concentric circle. The Radar display indicates the Short Term Loudness measured over time within a 3 sec. window. The consistency of the Short Term Loudness is evident indicating optimized intelligibility.
Section F displays the unprocessed source audio that lacks optimization for Internet/Mobile, and Podcast distribution. Any attempt to consume the audio in it’s current state in a less than ideal listening environment will result in compromised intelligibility. Mobile device consumption in like environments will exacerbate compromised intelligibility.
Section G displays the processed/optimized audio suitable for the noted distribution platform. The Integrated Loudness, True Peak, and LRA descriptors now satisfy compliance targets. Notice there is no indication of excessive limiting.
I thought I’d revisit various aspects of Loudness Meter Absolute/Relative Scale correlation, and provide a visual representation of a real time processing Session with both Scales active.
Descriptors and Scales
Modern Loudness Meters display various descriptors including Program Loudness – also referred to as Integrated Loudness. There are two scales that can be used to display measured Program or Integrated Loudness over time …
The most common is an Absolute Scale, displayed in LUFS or LKFS. LUFS refers to Loudness Units relative to Full Scale. LKFS refers to Loudness Units K-Weighted relative to Full Scale. There is no difference in the perceptual measured loudness between both descriptor references.
It is also possible to measure and display Integrated/Program Loudness as Loudness Units (or LU’s) on a Relative Scale where 1LU == 1 dB.
When shifting to a Relative Scale, the 0 LU increment is always equivalent to the Meter’s user defined or spec. defined Absolute Loudness target.
For example, in an R128 -23.0 LUFS Absolute Scale workflow, setting the Meter to display a Relative Scale changes the target to 0 LU.
So – if a piece of measured audio checks in at -23.0 LUFS on an Absolute Scale, it would be perceptually equal to measured audio checking in at 0 LU on a Relative Scale.
Likewise if the Meter’s Absolute Scale target is set to -16.0 LUFS, it will correlate to 0 LU on a Relative Scale. Again both would reflect perceptual equivalence.
All broadcast delivery specifications suggest Absolute Scale Integrated Loudness targets. However, for any number of subjective reasons – many operators prefer to use the alternative Relative Scale and “mix or master to 0 LU.”
Please note Loudness Units are also the proper way in which to describe Loudness differentials between two programs. For instance, “Program (A) is +2 LU louder than Program (B).” One might also describe gain offsets in LU’s as opposed to dB’s.
LU Meter
Hornet Plugins recently released Hornet LU Meter. This tool is a Loudness Meter plugin designed to measure and display Integrated/Program Loudness within a 400ms time window. This measurement represents the Momentary Loudness descriptor.
The Meter is indeed nifty and affordable. However there is one sort of caveat worth noting: As the name suggests, it is an LU Meter. In essence Integrated (Momentary) Loudness measurements are solely displayed on a Relative Scale.
Session
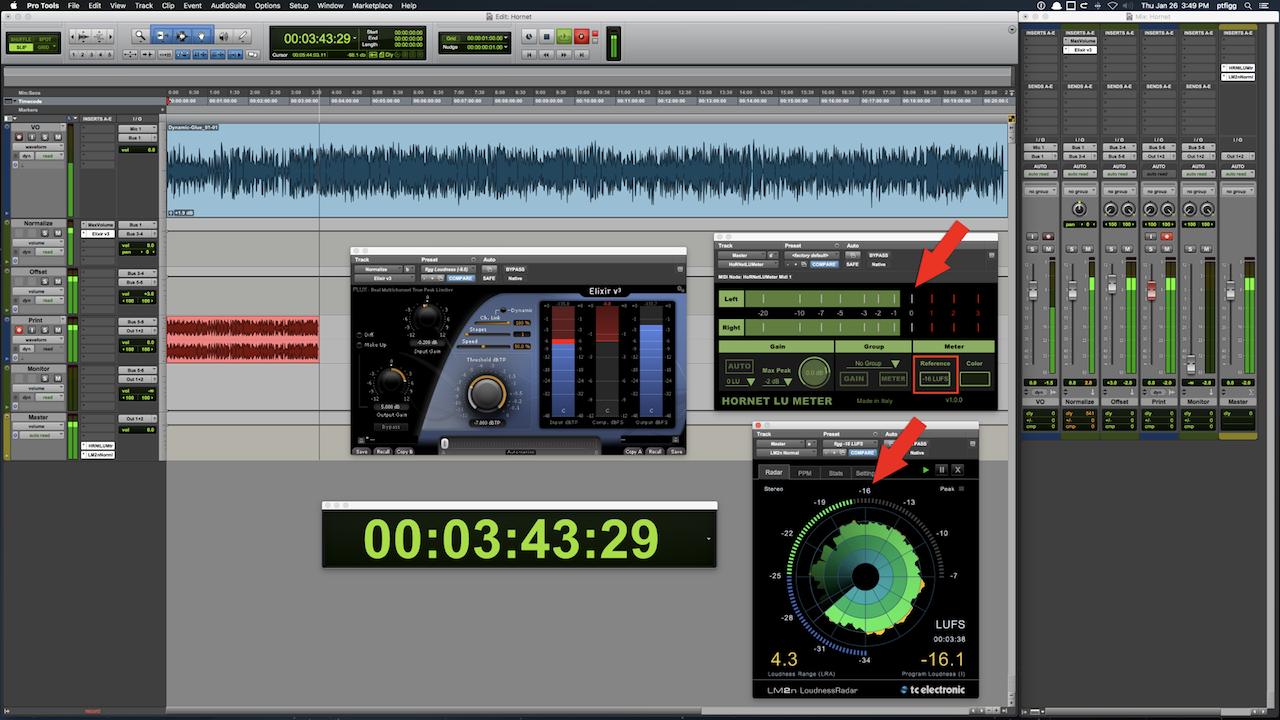
The displayed Session (image) consists of a single mono VO clip. The objective is to print a processed stereo version in RT checking in at -16.0 LUFS with a maximum True Peak no higher than -2.0 dBTP.
The output of the mono VO track is routed to a mono Auxiliary Input track titled Normalize. If you are not familiar with Pro Tools, an Auxiliary Input track is not the same as an Auxiliary Send. Auxiliary Input tracks allow the user to pass signal using buses, insert plugins, and adjust level. They are commonly used to create sub-mixes.
I’ve inserted a Compressor and a Limiter on the Normalize Auxiliary Input track. The processed audio is passing through at -19.0 LUFS (mono).
The audio is then routed to a second (now stereo) Auxiliary Input track titled Offset. I use the track fader to apply a +3 dB gain offset, This will reconstitute the loss of gain that occurs on center panned mono tracks. The attenuation is a direct result of the Pro Tools Pan Depth setting.
The signal flow/output is now passing -16.0 LUFS audio. It is routed to a standard audio track titled Print. When this track is armed to record, it is possible to initiate a realtime bounce of the processed/routed audio.
The Meters
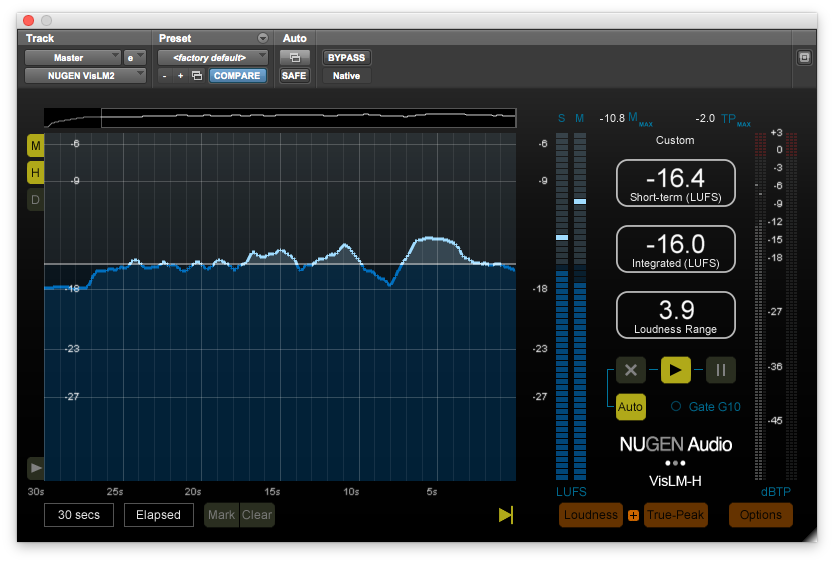
Notice the instances of the Hornet LU Meter and TC Electronics Loudness Radar. Both Meters are inserted on the Master Bus and are measuring the session’s Master Output.
I set the Reference (target) on the Hornet LU Meter to -16.0 LUFS. In essence 0 LU on it’s Relative Scale represents -16.0 LUFS.
Conversely the TC Electronic Meter is configured to display Absolute Scale measurements. The circular LED that borders the Radar area indicates Momentary Loudness. The defined Integrated Loudness target is displayed under the arrow at the 12 o’clock position.
Remember the Hornet LU Meter solely displays Momentary Loudness. If you compare it’s current reading to the indication of Momentary Loudness on the TC Electronic Meter, the relationship between Relative Scale and Absolute Scale measurement is clearly indicated. Basically the Hornet Meter registers just below 0 LU. The TC Electronic Meter registers just below -16.0 LUFS.
I will say if you are comfortable monitoring real time Momentary Loudness and understand Relative/Absolute Scale correlation, the Hornet tool is quite useful. In fact it contains additional features such as Grouping, auto/manual Gain Compensation, and auto-Maximum Peak protection.
Additional insight on the K-weighting Curve or K-weighted filtering:
K-weighting suggests de-emphasized low frequencies by way of a high-pass filter. A high-shelving filter is applied to the upper frequency range, and the measured data is averaged.
TC Electronic describes applied K-weighting on audio channels as a “method to build a bridge between subjective impression and objective measurement.”
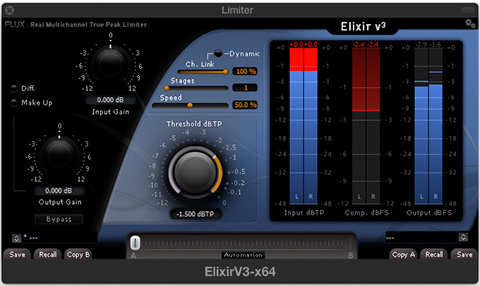
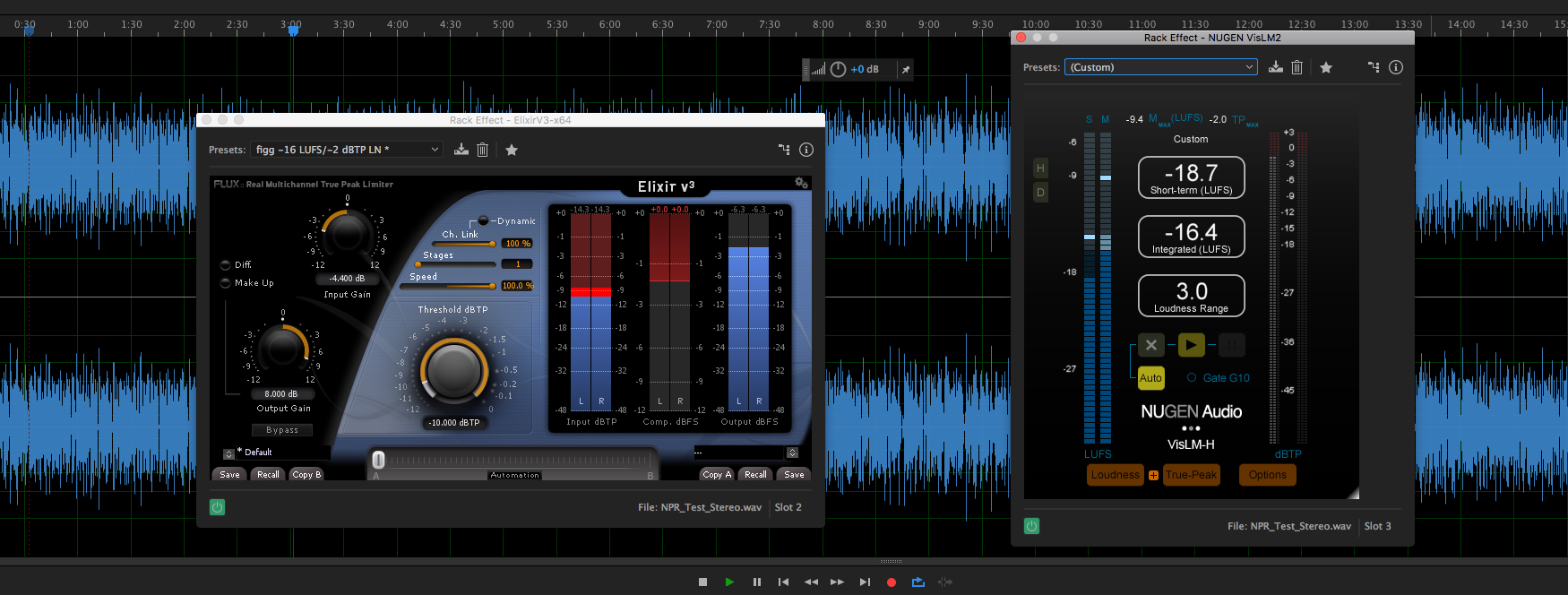
Certain ISP/True Peak Limiters provide added compliance processing flexibility. Case in point: Elixir by Flux.
Preparation
Before processing or Loudness Normalizing, execute an offline measurement on an optimized source clip.
An optimized audio clip may exhibit the benefits of various stages of enhancement processing such as noise reduction and dynamic range compression.
The displayed clip (see attached image) checks in at -19.6 LUFS. It requires +3.6 dB of gain to meet a -16.0 LUFS Integrated Loudness target. Based on the pre-existing peak ceiling approximately 1.5 dB of limiting will be necessary to establish a -2.0 True Peak maximum.
Processing Example
We use the Limiter’s Input Gain setting to take the clip down to -24.0 LUFS (-4.4 dB for the measured displayed clip).
The initial -24.0 LUFS target will restore headroom and establish a consistent starting point for downstream limiting accuracy. This will allow the Threshold and Output Gain settings to be recognized and implemented as static parameters for all -16.0 LUFS/-2.0 dBTP (stereo) processing. The Input Gain setting however will be variable based on the measured attributes of the optimized source.
Set the Threshold to -10 dB(TP) and the Output Gain to +8dB. The processing may be implemented offline or in real time. The output audio will reflect accurate targets (-16.0 LUFS/-2.0 dBTP) and the applied limiting will be transparent.
Note:
The proprietary functional parameters included on the Elixir Limiter are not necessarily included on Limiters designed by competing developers. In essence the described workflow may need to be customized based on the attributes of the Limiter.
The key is the “math” and static parameters never change, unless of course you decide to alter the referenced targets.
This is a re-post of an article that I published in October, 2015 …
In a recent Midroll article titled “Why Programmatic Ads Aren’t Necessarily Great for Podcasting,” the staff writer states:
“A number of players in the Podcasting and advertising industries are making bets on programmatic Ad delivery — dynamically inserting Ads into a Podcast as the episode is downloaded. It’s an understandable temptation, but we at Midroll see some tradeoffs.”
I wonder how networks will handle potential perceived Loudness inconsistencies between produced Ads and new or preexisting programs?
I’ve mentioned my past affiliation with IT Conversations and The Conversations Network, where I was the lead post audio engineer from 2005-2012. Executive Director Doug Kaye built a proprietary content management system and infrastructure that included an automated component based Show Assembly System. Audio components were essentially audio clips (Intros, Outros, Ads, Credits. etc.) combined server side into Podcasts in preparation for distribution.
One key element in this implementation was the establishment of perceived Loudness consistency across all submitted audio components. This was accomplished by standardizing an average Loudness Target using a proprietary software RMS Normalizer to process all server side audio components prior to assembly. (Loudness Normalization is now the recommended process for Integrated Loudness targeting and consistency).
Due to this consistency, all distributed Podcasts were perceptually equal with regard to Integrated or Program Loudness upon playback. This was for the benefit of the listener, removing the potential need to make constant playback volume adjustments within a single program and throughout all programs distributed on the network.
Regarding Programmatic Ad insertion, I have yet to come across a Podcast Network that clearly states a set Integrated Loudness Target for submitted programs. (A Maximum True Peak requirement is equally important. However this descriptor has no effect on perceptual Loudness consistency).
Due to the absence of any suggested internal network guidelines or any form of standardized Loudness Normalization, dynamic Ad insertion has the potential to ruin the perceptual consistency within single programs and throughout the contents of an entire network.
Many conscientious independent producers have embraced the credible -16.0 LUFS Integrated Loudness Target for stereo Internet/ Mobile/Podcast audio distribution (the perceptual equivalent for mono distribution is -19.0 LUFS). It’s far from a requirement, and nothing more than a suggested guideline.
My hope is Podcast Networks will begin to recognize the advantages of standardization and consider the adoption of the -16.0 LUFS Integrated Loudness Target. Dynamically inserted Ads must be perceptually equal to the parent program. Without a standardized and pre-disclosed Integrated Loudness Target, it will be near impossible to establish any level of distribution consistency.
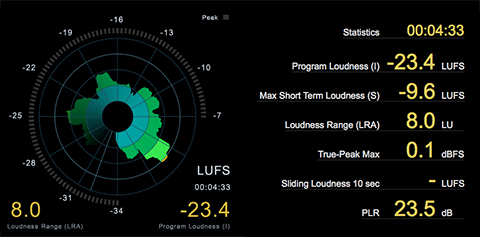
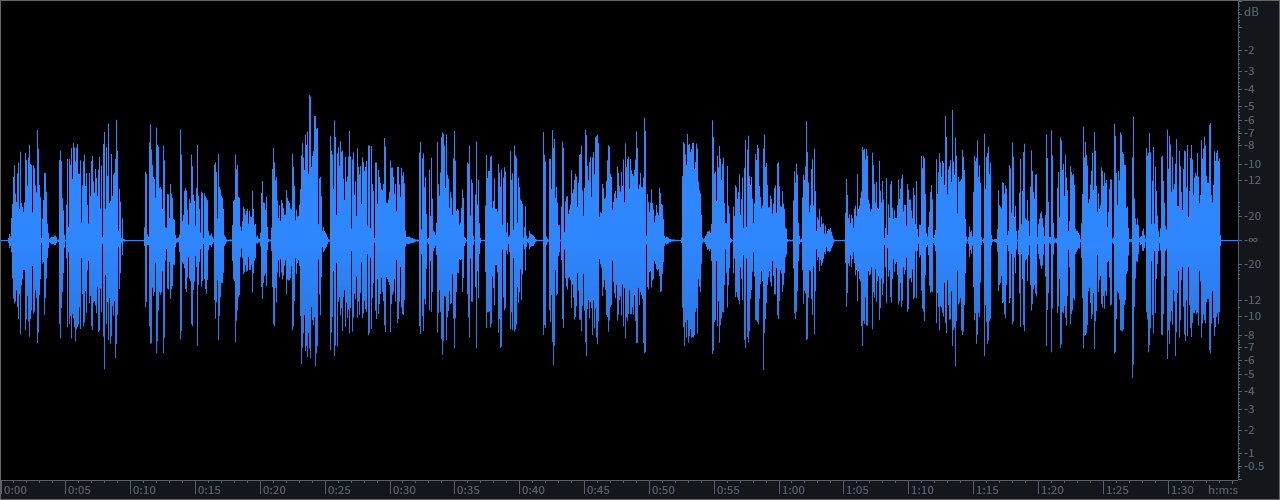
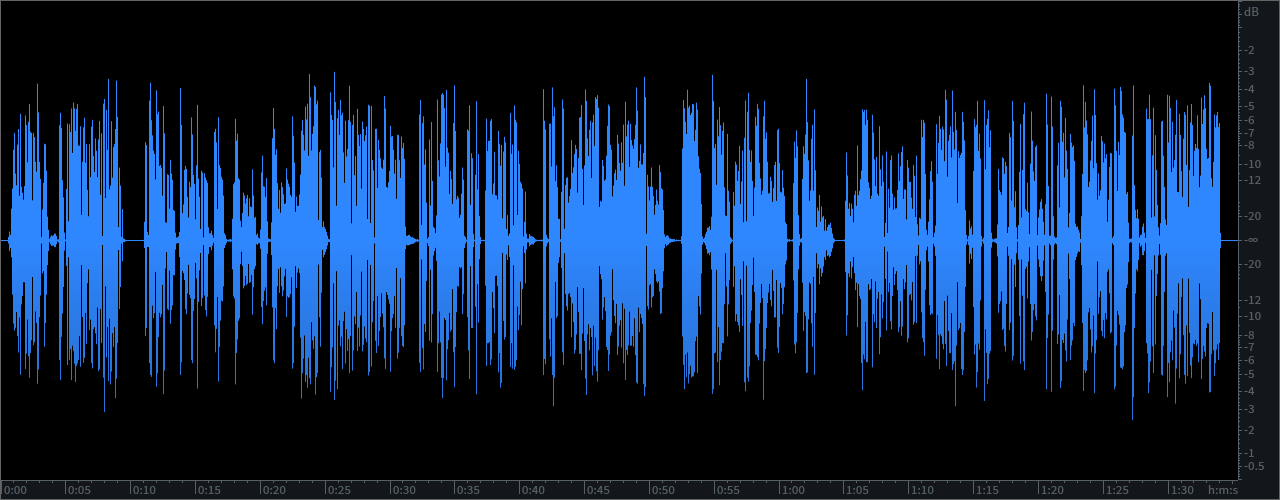
I recently analyzed a few of the internal Podcasts produced by CNN. One particular installment is yet another example of a major media outlet distributing audio that is in my view unsuitable for this particular platform.
Let’s discuss file attributes and measured specs. for one of CNN’s distributed Podcasts:
The distributed audio is mono, 64kbps, with music elements. I’ve stated how I feel about this. I’m not a proponent of 64 kbps MP3 audio PERIOD (mono or stereo). In general audio in this format sounds horrible. Feel free to disagree.
Secondly, the Integrated (Program) Loudness for this particular program is just about -23.0 LUFS with a Maximum True Peak of +0.40 dBTP. From my perspective the perceptual Loudness misses the mark. And, the audio is clipped.
Lastly, the produced audio is way too dynamic for spoken word. The perceptual inconsistency of the delivery by the participants is inadequate when considering how (for the most part) this program will be consumed (mobile devices, problematic ambient spaces, etc.).
I decided to sort of showcase this particular program because it is a good candidate for flexible Target considerations. What do I mean by “flexible Target considerations?” Let me explain …
Again, the distributed file is mono. The recommended Integrated Loudness Target for mono Podcasts is -19.0 LUFS. This is the perceptual equivalent of -16.0 LUFS stereo. If I were to apply a +4 db gain offset to Loudness Normalize this audio to -19.0 LUFS, there would be very little change in the original dynamic structure of the audio. However without some form of aggressive limiting, the maximum amplitude or Peak Ceiling would be driven into oblivion. In fact audible distortion may occur with or without limiting. This is obviously not recommended.
There are two options to consider: 1) apply Dynamic Range Compression before Loudness Normalization, or 2) shoot for a lower Integrated Loudness target. For this particular example I chose to implement both options.
First, in my view optimizing the dynamics in this program for Podcast distribution is unavoidable. It’s just way too choppy and it lacks delivery consistency for spoken word. Also, by lowering the L.Normalized Target, the necessary added gain offset will be reduced resulting in less aggressive limiting. In addition, the reduced amount of added gain will curtail noise floor elevation and other variables such as exaggerated breaths.
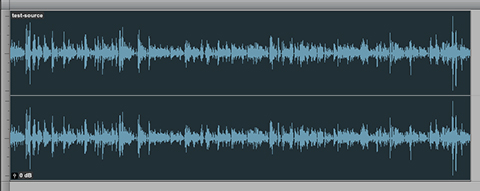
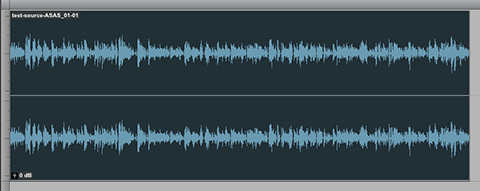
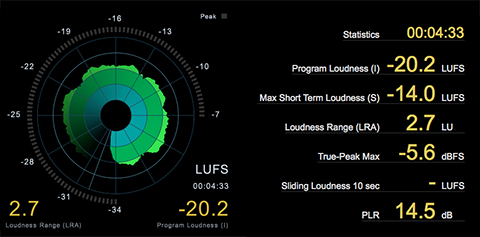
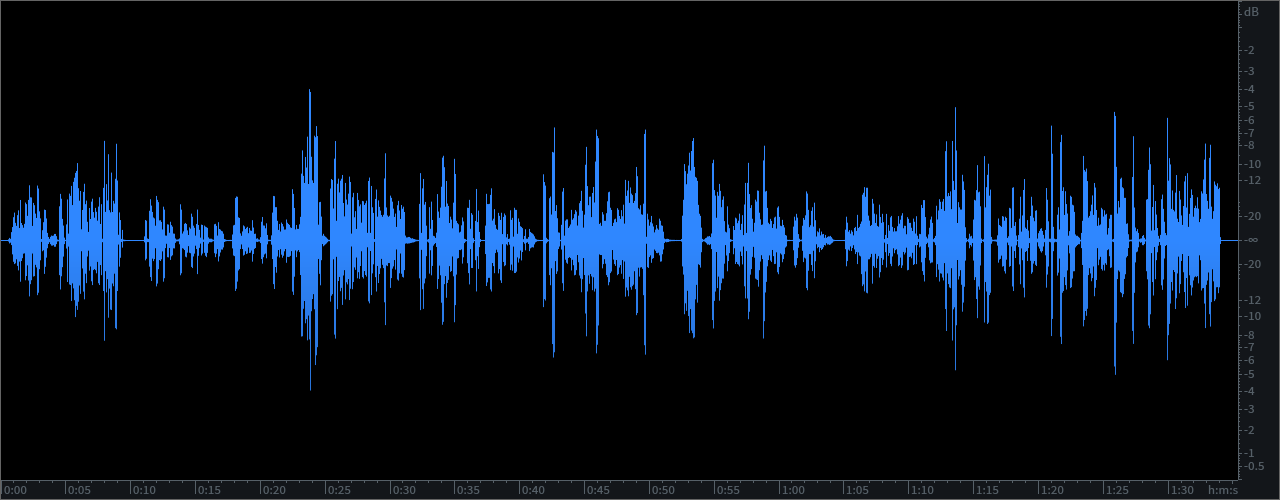
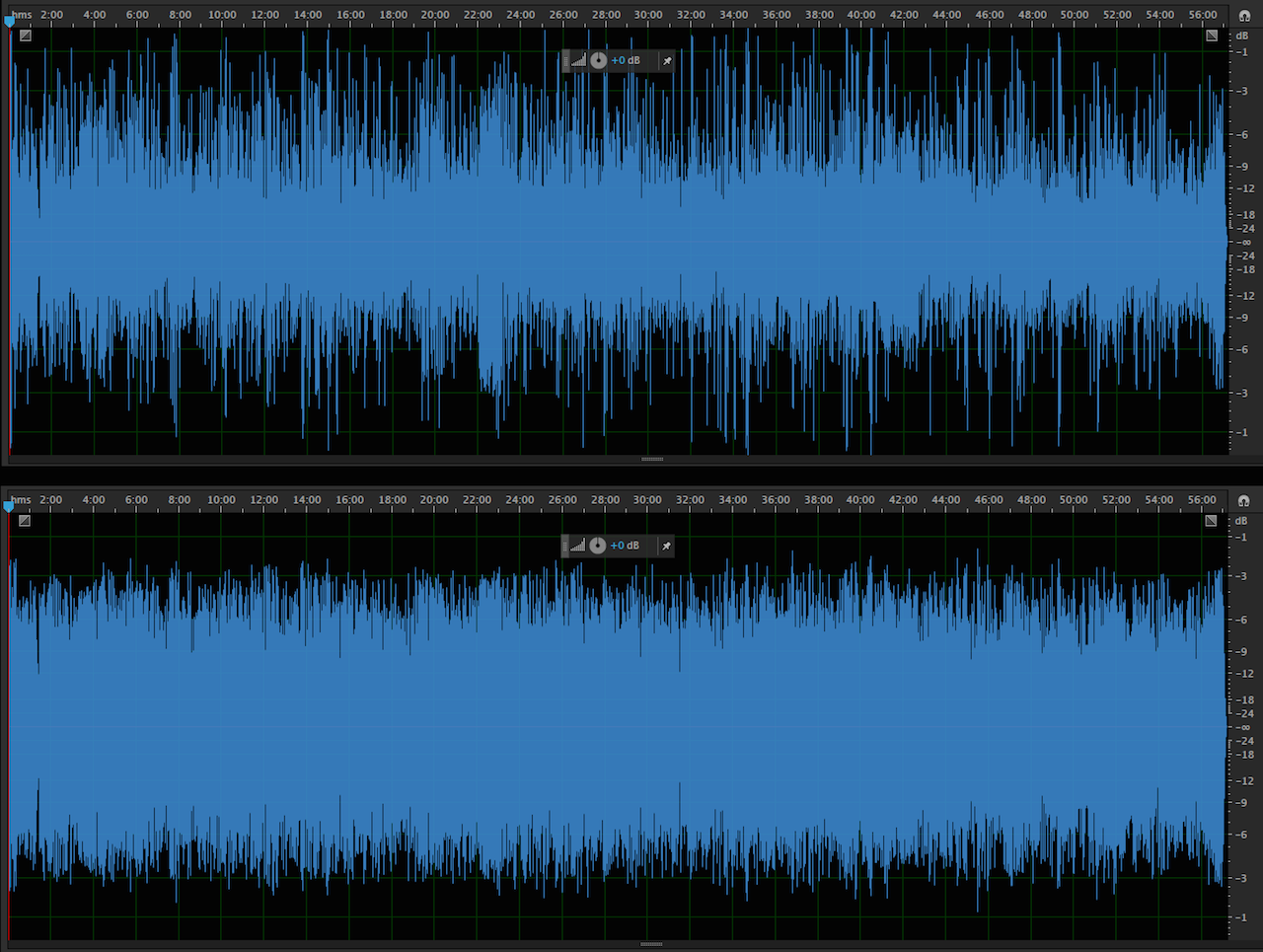
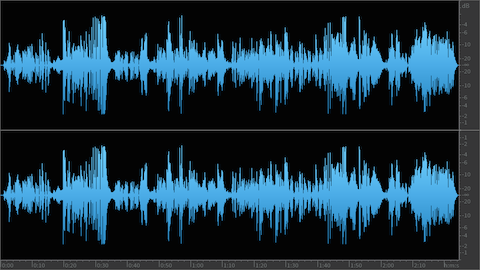
As noted the distributed Podcast (displayed in the attached upper waveform example) checks in at -23.0 LUFS and it is clipped. My optimized version (displayed in the lower waveform example) checks in at -20.2 LUFS with a Maximum True Peak of -1.23 dBTP. It is well within a reasonable level of Program Loudness tolerance for Podcast L.Normalization. In fact the perceptual difference between the processed -20.0 LUFS audio and a -19.0 LUFS version would be pretty much undetectable. In essence the audio has been optimized and it exhibits improved intelligibility. It is now well suited for Podcast distribution.
(If you are interested in the tools that I use, they are listed under Available Services).
It is no secret that I am a staunch proponent of the -16.0 LUFS/-19.0 LUFS recommendations for Podcasts. However, in certain situations – tolerance for slightly reduced Program Loudness Targets is acceptable.
For the record – my remaster is much easier to listen to. CNN can do better.
I’d like to share my observations and views on the recently published AES Technical Document AES TD1004.1.15-10 that specifics best practices for Loudness of Audio Streaming and Network File Playback.
The document is a collection of Loudness processing guidelines for diverse platform dependent media streaming and downloading. This would include music, spoken word, and possible high dynamic audio in video streams. The document credits some of the most well respected industry leading professionals, including Bob Katz, Thomas Lund, and Florian Camerer. The term “Podcast” is directly referenced once in the document, where the author(s) state:
“Network file playback is on-demand download of complete programs from the network, such as podcasts.”
I support the purpose of this document, and I understand the stated recommendations will most likely evolve. However in my view the guidelines have the potential to create a fair amount of confusion for producers of spoken word content, mainly Podcast producers. I’m specifically referring to the suggested 4 LU range (-16.0 to -20.0 LUFS) of acceptable Integrated Loudness Targets and the solutions for proper targeting.
Indeed compliance within this range will moderately curtail perceptual loudness disparities across a wide range of programs. However the leniency of this range is what concerns me.
I am all for what I refer to as reasonable deviation or “wiggle room” in regard to Integrated Loudness Target flexibility for Podcasts. However IMHO a -20 LUFS spoken word Podcast approaches the broadcast Loudness Targets that I feel are inadequate for this particular platform. A comparable audio segment with wide dynamics will complicate matters further.
I also question the notion (as stated in the document) of purposely precipitating clipping when adding gain “to handle excessive peaks.”
And there is no mention of the perceptual disparities between Mono and Stereo files Loudness Normalized to the same Integrated Loudness Target. For the record I don’t support mono file distribution. However this file format is prevalent in the space.
Perspective
I feel the document’s perspective is somewhat slanted towards platform dependent music streaming and preservation of musical dynamics. In this category, broad guidelines are for the most part acceptable. This is due to the wide range of production techniques and delivery methods used on a per musical genre basis. Conversely spoken word driven audio is not nearly as artistically diverse. Considering how and where most Podcasts are consumed, intelligibility is imperative. In my view they require much more stringent guidelines.
It’s important to note streaming services and radio stations have the capability to implement global Loudness Normalization. This frees content creators from any compliance responsibilities. All submitted media will be adjusted accordingly (turned up or turned down) in order to meet the intended distribution Target(s). This will result in consistency across the noted platform.
Unfortunately this is not the case in the now ubiquitous Podcasting space. At the time of this writing I am not aware of a single Podcast Network that (A) implements global Loudness Normalization … and/or … (B) specifies a requirement for Integrated Loudness and Maximum True Peak Targets for submitted media.
Currently Podcast Loudness compliance Targets are resolved by each individual producer. This is the root cause of wide perceptual loudness disparities across all programs in the space. In my view suggesting a diverse range of acceptable Targets especially for spoken word may further impede any attempts to establish consistency and standardization.
PLR and Retention of Music Dynamics
The document states: “Users may choose a Target Loudness that is lower than the -16.0 LUFS maximum, e.g., -18.0 LUFS, to better suit the dynamic characteristics of the program. The lower Target Loudness helps improve sound quality by permitting the programs to have a higher Peak to Loudness Ratio (PLR) without excessive peak limiting.”
The PLR correlates with headroom and dynamic range. It is the difference between the average Loudness and maximum amplitude. For example a piece of audio Loudness Normalized to -16.0 LUFS with a Maximum True Peak of -1 dBTP reveals a PLR of 15. As the Integrated Loudness Target is lowered, the PLR increases indicating additional headroom and wider dynamics.
In essence low Integrated Loudness Targets will help preserve dynamic range and natural fidelity. This approach is great for music production and streaming, and I support it. However in my view this may not be a viable solution for spoken word distribution, especially considering potential device gain deficiencies and ubiquitous consumption habits carried out in problematic environments. In fact in this particular scenario a moderately reduced dynamic range will improve spoken word intelligibility.
Recommended Processing Options and Limiting
If a piece of audio is measured in it’s entirety and the Integrated Loudness is higher than the intended Target, a subtractive gain offset normalizes the audio. For example if the audio checks in at -18.0 LUFS and you are targeting -20.0 LUFS, we simply subtract 2 dB of gain to meet compliance.
Conversely when the measured Integrated Loudness is lower than the intended Target, Loudness Normalization is much more complex. For example if the audio checks in at -20.0 LUFS, and the Integrated Loudness Target is -16.0 LUFS, a significant amount of gain must be added. In doing so the additional gain may very well cause overshoots, not only above the Maximum True Peak Target, but well above 0dBFS. Inevitably clipping will occur. From my perspective this would clearly indicate the audio needs to be remixed or remastered prior to Loudness Normalization.
Under these circumstances I would be inclined to reestablish headroom by applying dynamic range compression. This approach will certainly curtail the need for aggressive limiting. As stated the reduced dynamic range may also improve spoken word intelligibility. I’m certainly not suggesting aggressive hyper-compression. The amount of dynamic range reduction is of course subjective. Let me also stress this technique may not be suitable for certain types of music.
Additional Document Recommendations and Efficiency
The authors of the document go on to share some very interesting suggestions in regard to effective Loudness Normalization:
1) “If level has to be raised, raise until it reaches Target level or until True Peak reaches 0 dBTP, whichever occurs first. Thus, the sound quality will be preserved, without introducing excessive peak limiting.”
2) “Perform what is noted in example 1, but keep raising the level until the program level reaches Target, and apply either peak limiting or allow some clipping to handle excessive peaks. The advantage is more consistent loudness in the stream, but this is a potential sonic compromise compared to example 1. The best way to retain sound quality and have more consistent loudness is by applying example 1 and implementing a lower Target.”
With these points in mind, please review/demo the following spoken word audio segment. In my opinion the audio in it’s current state is not optimized for Podcast distribution. It’s simply too low in terms of perceptual loudness and too dynamic for effective Loudness Normalization, especially if targeting -16.0 LUFS. Due to these attributes suggestion 1 above is clearly not an option. In fact neither is option 2. There is simply no available headroom to effectively add gain without driving the level well above full scale. Peak limiting is unavoidable.
I feel the document suggestions for the segment above are simply not viable, especially in my world where I will continue to recommend -16.0 LUFS as the recommended Target for spoken word Podcasts. Targeting -18.0 LUFS as opposed to -16.0 LUFS is certainly an option. It’s clear peak limiting will still be necessary.
Below is the same audio segment with dynamic range compression applied before Loudness Normalization to -16.0 LUFS. Notice there is no indication of aggressive limiting, even with a Maximum True Peak of -1.7 dBTP.
Regarding peak limiting the referenced document includes a few considerations. For example: “Instead of deciding on 2 dB of peak limiting, a combination of a -1 dBTP peak limiter threshold with an overall attenuation of 1 dB from the previously chosen Target may produce a more desirable result.”
This modification is adequate. However the general concept continues to suggest the acceptance of flexible Targets for spoken word. This may impede perceptual consistency across multiple programs within a given network.
Conclusion
The flexible best practices suggested in the AES document are 100% valid for music producers and diverse distribution platforms. However in my opinion this level of flexibility may not be well suited for spoken word audio processing and distribution.
I’m willing to support the curtailment of heavy peak limiting when attempting to normalize spoken word audio (especially to -16.0 LUFS) by slightly reducing the intended Integrated Loudness Target … but not by much. I will only consider doing so if and when my personal optimization methods prior to normalization yield unsatisfactory results.
My recommendation for Podcast producers would be to continue to target -16.0 LUFS for stereo files and -19.0 LUFS for mono files. If heavy limiting occurs, consider remixing or remastering with reduced dynamics. If optimization is unsuccessful, consider lowering the intended Integrated Loudness Target by no more than 2 LU.
A True Peak Maximum of <= -1.0 dBTP is fine. I will continue to suggest -1.5 dBTP for lossless files prior to lossy encoding. This will help ensure compliance in encoded lossy files. What’s crucial here is a full understanding of how lossy, low bit rate coders will overshoot peaks. This is relevant due to the ubiquitous (and not necessarily recommended) use of 64kbps for mono Podcast audio files.
Let me finish by stating the observations and recommendations expressed in this article reflect my own personal subjective opinions based on 11 years of experience working with spoken word audio distributed on the Internet and Mobile platforms. Please fell free to draw your own conclusions and implement the techniques that work best for you.
I’ve discussed the reasons why there is a need for revised (optimized) Loudness Standards for Internet and Mobile audio distribution. Problematic (noisy) consumption environments and possible device gain deficiencies justify an elevated Integrated Loudness target. Highly dynamic audio complicates matters further.
In essence audio for the Internet/Mobile platform must be perceptually louder on average compared to audio targeted for Broadcast. The audio must also exhibit carefully constrained dynamics in order to maintain optimized intelligibility.
The recommended Integrated Loudness targets for Internet and Mobile audio are -16.0 LUFS for stereo files and -19.0 LUFS for mono. They are perceptually equal.
In terms of Dynamics, I’ve expressed my opinion regarding compression. In my view spoken word audio intelligibility will be improved after careful Dynamic Range Compression is applied. Note that I do not advocate aggressive compression that may result in excessive loudness and possible quality degradation. The process is a subjective art. It takes practice with accessibility to well designed tools along with a full understanding of all settings.
I thought I would discuss various aspects of Podcast audio Dynamics. Mainly, the potential problematic significance of wide Dynamics and how to quantify aspects as such using various descriptors and measurement tools. I will also discuss the benefits of Dynamic Range management as a precursor to Loudness Normalization. Lastly I will disclose recommended benchmarks that are certainly not requirements. Feel free to draw your own conclusions and target what works best for you.
Highly Dynamic Audio in Noisy Environments
At it’s core extended or Wide Dynamic Range describes notable disparities between high and low level passages throughout a piece of audio. When this is prevalent in a spoken word segment, intelligibility will be compromised – especially in situations where the listening environment is less than ideal.
For example if you are traveling below Manhattan on a noisy subway, and a Podcast talent’s delivery is inconsistent, you may need to make realtime playback volume adjustments to compensate for any inconsistent high and low level passages.
As well – if the Integrated Loudness is below what is recommended, the listening device may be incapable of applying sufficient gain. Dynamic Range Compression will reestablish intelligibility.
From a post perspective – carefully constrained dynamics will provide additional headroom. This will optimize audio for further down stream processing and ultimately efficient Loudness Normalization.
Dynamic Range Compression and Loudness Normalization
I would say in most cases successful Loudness Normalization for Broadcast compliance requires nothing more than a simple subtractive gain offset. For example if your mastered piece checks in at -20.0 LUFS (stereo), and you are targeting R128 (-23.0 LUFS Integrated), subtracting -3 LU of gain will most likely result in compliant audio. By doing so the original dynamic attributes of the piece will be retained.
Things get a bit more complicated when your Integrated Loudness target is higher than the measured source. For example a mastered -20.0 LUFS piece will require additional gain to meet a -16.0 LUFS target. In this case you may need to apply a significant amount of limiting to prevent the Maximum True Peak from exceeding your target. In essence without safeguards, added gain may result in clipping. The key is to avoid excessive limiting if at all possible.
How do we optimize audio before a gain offset is applied?
I recommend applying a moderate to low amount of (global) final stage Dynamic Range Compression before Loudness Normalization. When processing highly dynamic audio this final stage compression will prevent instances of excessive limiting. The amount of compression is of course subjective. Often a mere 1-2 dB of gain reduction will be sufficient. Effectiveness will always depend on the attributes of the mastered source audio before L.Normalizing.
I carefully manage spoken word dynamics throughout client project workflows. I simply maintain sufficient headroom prior to Loudness Normalization. In most cases I am able to meet the intended Integrated Loudness and Maximum True Peak targets (without limiting) by simply adding gain.
RX Loudness Control
By design iZotope’s RX Loudness Control also applies compression in certain instances of Loudness Normalization. I suggest you read through the manual. It is packed with information regarding audio loudness processing and Loudness Normalization.
iZotope states the following:
“For many mixes, dynamics are not affected at all . This is because only a fixed gain is required to meet the spec . However, if your mix is too dynamic or has significant transients, compression and/or limiting are required to meet Short-term/Momentary or True Peak parts of the spec.”
“RX Loudness Control uses compression in a way that preserves the quality of your audio . When needed, a compressor dynamically adjusts your audio to ensure you get the best sound while remaining compliant . For loudness standards that require Short-term or Momentary compliance, the compressor is engaged automatically when loudness exceeds the specified target.”
It’s a highly recommended tool that simplifies offline processing in Pro Tools. Many of it’s features hook into Adobe’s Premiere Pro and Media Encoder.
LRA, PLR, and Measurement Tools
So how do we quantify spoken word audio dynamics? Most modern Loudness Meters are capable of calculating and displaying what is referred to as the Loudness Range (LRA). This particular descriptor is displayed in Loudness Units (LU’s). Loudness Range quantifies the differences in loudness measurements over time. This statistical perspective can help operators decide whether Dynamic Range Compression may be necessary for optimum intelligibility on a particular platform. (Note in order to prevent a skewed measurement due to various factors – the LRA algorithm incorporates relative and absolute threshold gating. For more information: refer to EBU Tech doc 3342).
I will say before I came across sort of rule of thumb (recommended) guidelines for Internet and Mobile audio distribution, the LRA in the majority of the work that I’ve produced over the years hovered around 3-5 LU. In the highly regarded article Audio for Mobile TV, iPad and iPod, the author and leading expert Thomas Lund of TC Electronic suggests an LRA not much higher than 8 LU for optimal Pod Listening. Basically higher LRA readings suggest inconsistent dynamics which in turn may not be suitable for Mobile platform distribution.
Some Loudness Meters also display the PLR descriptor, or Peak to Loudness Ratio. This correlates with headroom and dynamic range. It is the difference between the Program (average) Loudness and maximum amplitude. Assuming a piece of audio has been Loudness normalized to -16.0 LUFS along with an awareness of a True Peak Maximum somewhere around -1.0 dBTP, it is easy to recognize the general sweet spot for the Mobile platform ->> (e.g. a PLR reasonably less than 16 for stereo).
Note that heavily compressed or aggressively limited (loud) audio will exhibit very low PLR readings. For example if the measured Integrated Loudness of a particular program is -10.0 LUFS with a Maximum True Peak of -1.0 dBTP, the reduced PLR (9) clearly indicates aggressive processing resulting in elevated perceptual loudness. This should be avoided.
If you are targeting -16.0 LUFS (Integrated), and your True Peak Maximum is somewhere between -1.0 and -3.0 dBTP, your PLR is well within the recommended range.
In Conclusion
An optimal LRA is vital for Podcast/Spoken Word distribution. Use it to gauge delivery consistency, dynamics, and whether further optimization may be necessary. At this point in time I suggest adhering to an LRA < 7 LU for spoken word.
LRA Measurements may be performed in real time using a compliant Loudness Meter such as Nugen Audio’s VisLM 2, TC Electronic’s LM2n Loudness Radar, and iZotope’s Insight (also check out the Youlean Loudness Meter). Some meters are capable of performing offline measurements in supported DAWs. There are a number of stand alone third party measurement options available as well, such as iZotope’s RX7 Advanced Audio Editor, Auphonic Leveler, FFmpeg, and r128x.
-paul.
***Please note I personally paid for my RX Loudness Control license and I have no formal affiliation with iZotope.
Two copies of an audio file. File 1 is Stereo, Loudness Normalized to -16.0 LUFS. File 2 is Mono, also Loudness Normalized to -16.0 LUFS.
Passing both files through a Loudness Meter confirms equal numerical Program Loudness. However the numbers do not reflect an obvious perceptual difference during playback. In fact the Mono file is perceptually louder than it’s Stereo counterpart.
Why would the channel configuration affect perceptual loudness of these equally measured files?
The Explanation
I’m going to refer to a feature that I came across in a Mackie Mixer User Manual. Mackie makes reference to the “Constant Loudness” principle used in their mixers, specifically when panning Mono channels.
On a mixer, hard-panning a Mono channel left or right results in equal apparent loudness (perceived loudness). It would then make sense to assume that if the channel was panned center, the output level would be hotter due to the combined or “mixed” level of the channel. In order to maintain consistent apparent loudness, Mackie attenuates center panned Mono channels by about 3 dB.
We can now apply this concept to the DAW …
A Mono file played back through two speakers (channels) in a DAW would be the same as passing audio through a Mono analog mixer channel panned center. In this scenario, the analog mixer (that adheres to the Constant Loudness principle) would attenuate the output by 3dB.
In order to maintain equal perception between Loudness Normalized Stereo and Mono files targeting -16.0 LUFS, we can simulate the Constant Loudness principle in the DAW by attenuating Mono files by 3 LU. This compensation would shift the targeted Program Loudness for Mono files to -19.0 LUFS.
To summarize, if you plan to Loudness Normalize to the recommend targets for internet/mobile, and Podcast distribution … Stereo files should target -16.0 LUFS Program Loudness and Mono files should target -19.0 LUFS Program Loudness.
Note that In my discussions with leading experts in the space, it has come to my attention that this approach may not be sustainable. Many pros feel it is the responsibility of the playback device and/or delivery system to apply the necessary compensation. If this support is implemented, the perceived loudness of -16.0 LUFS Mono will be equal to -16.0 LUFS Stereo. There would be no need to apply manual compensation.
In my previous article I discussed various aspects of the Match Volume Processor in Adobe Audition CC. I mentioned that the ITU Loudness processing option must be used with care due to the lack of support for a user defined True Peak Ceiling.
Here’s how to implement the off-line processing version in Audition CC …
This is a snapshot of a stereo version of what may very well be the second most popular podcast in existence:
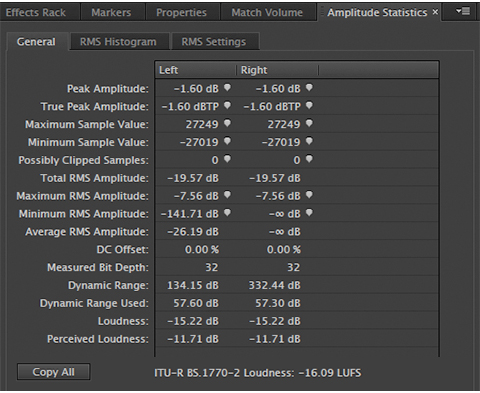
Amplitude Statistics in Audition:
Peak Amplitude:0dB
True Peak Amplitude:0.18dBTP
ITU Loudness:-15.04 LUFS
It appears the producer is Peak Normalizing to 0dBFS. In my opinion this is unacceptable. If I was handling post production for this program I would be much more comfortable with something like this at the source:
Amplitude Statistics in Audition:
Peak Amplitude:-0.81dB
True Peak Amplitude:-0.81dBTP
ITU Loudness:-15.88 LUFS
We will be shooting for the Internet/Mobile/Podcast target of -16.0 LUFS Program Loudness with a suitable True Peak Ceiling.
The first step is to run Amplitude Statistics and determine the existing Program Loudness. In this case it’s -15.88 LUFS. Next we need to Loudness Normalize to -24.0 LUFS. We do this by simply calculating the difference (-8.1) and applying it as a Gain Offset to the source file.
The next step is to implement a static processing chain (True Peak Limiter and secondary Gain Offset) in the Audition Effects Rack. Since these processing instances are static, save the Effects Rack as a Preset for future use.
Set the Limiter’s True Peak Ceiling to -9.5dBTP. Set the secondary Gain Offset to +8dB. Note that the Limiter must be inserted before the secondary Gain Offset.
Process, and you are done.
In this snapshot the upper waveform is the Loudness Normalized source (-24.0 LUFS). The lower waveform in the Preview Editor is the processed audio after it was passed through the Effects Rack chain.
In case you are wondering why the Limiter is before the secondary Gain instance – in a generic sense, if you start with -9.5 and add 8, the result will always be -1.5. This translates into the Limiter doing it’s job and never allowing the True Peaks in the audio to exceed -1.5dBTP. In essence this is the ultimate Ceiling. Of course it may be lower. It all depends on the state of the source file.
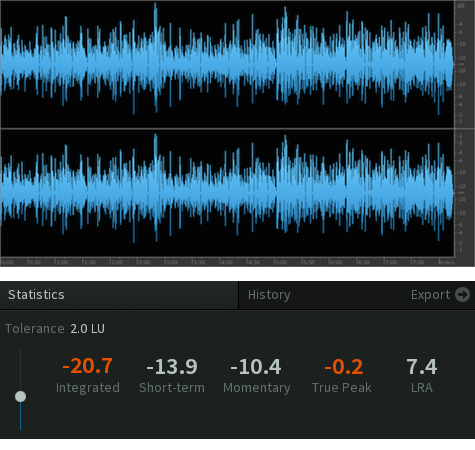
This last snapshot displays the processed audio that is fully compliant, followed by it’s Amplitude Statistics:
In Summary:
[– Determine Program Loudness of the source (Amplitude Statistics).
[– Loudness Normalize (Gain Offset) to -24.0 LUFS.
[– Run your saved Effects Rack chain that includes a True Peak Limiter (Ceiling set to -9.5dBTP) and a secondary +8dB Gain Offset.
*** UPDATE: Please note this post was written in 2014. The current version of Adobe Audition CC has been greatly enhanced, specifically in regards to the Match Loudness Module. It is now possible to define a True Peak Maximum, as well as Integrated/Program Loudness targets. It is also possible to customize Loudness Normalization Tolerence.
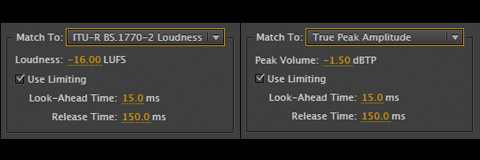
Adobe Audition CC has a handy Match Volume Processor with various options including Match To/ITU-R BS.1770-2 Loudness. The problem with this option is the Processor will not allow the operator to define a True Peak Ceiling. And so depending on various aspects of the input file, it’s possible the processed audio may not comply due to an unsuitable Peak Ceiling.
For example if you need to target -16.0 LUFS Program Loudness for internet/mobile distribution, the Match Volume Processor may need to increase gain in order to meet this target. Any time a gain increase is applied, you run the risk of pushing the Peak Ceiling to elevated levels.
The ITU Loudness processing option does supply a basic Limiting option. However – it’s sort of predefined. My tests revelaled Peak Ceilings as high as -0.1dBFS. This will result in insufficient headroom for both True Peak compliance and preparation for MP3 encoding.
The Audition Match Volume Processor also features a Match To/True Peak Amplitude option with a user defined True Peak Ceiling (referred to as Peak Volume). This is essentially a True Peak Limiter that is independent of the ITU Loudness Processor. For Program Loudness and True Peak compliance, it may be necessary to run both processing stages sequentially.
There are a few caveats …
[– If the Match Volume Processor (Match To/ITU-R BS.1770-2 Loudness) applies limiting that results in a Peak Ceiling close to full scale, any subsequent limiting (Match To/True Peak Amplitude) has the potential to reduce the existing Program Loudness.
[– If a Match Volume process (Match To/ITU-R BS.1770-2 Loudness) yields a compliant True Peak Ceiling right out of the box, there is no need to run any subsequent processing.
Conclusion
If you are going to use these processing options, my suggestion would be to make sure the measured Program Loudness of your input file is reasonably close to the Program Loudness that you are targeting. Also, make sure the input file has sufficient headroom, with existing True Peaks well below 0dBFS.
If you are finding it difficult to achieve acceptable results, I suggest you apply the concepts described in this video tutorial that I produced. I demonstrate a sort of manual “off-line” Loudness Normalization process. If you prefer to handle this in real time (on-line), refer to my article “Podcast Loudness Processing Workflow.”
Below is Elixir by Flux. This is an ITU-R BS.1770/EBU R128 compliant multichannel True Peak Limiter. It’s just one of the tools available that can be used in the workflow described below. In this post I also mention the ISL True Peak Limiter by Nugen Audio.
If you have any questions about these tools or Loudness Meters in general, ping me. In fact I think my next article will focus on the importance of learning how to use a Loudness Meter, so stay tuned …
In my previous post I made reference to an audio processing workflow recommended by Thomas Lund. The purpose of this workflow is to effectively process audio files targeting loudness specifications that are suitable for internet and mobile distribution. in other words – Podcasts.
“Mobile and computer devices have a different gain structure and make use of different codecs than domestic AV devices such as television. Tests have been performed to determine the standard operating level on Apple devices.
Based on 1250 music tracks and 210 broadcast programs, the Apple normalization number comes out as -16.2 LKFS (Loudness, K-weighted, relative to Full Scale) on a BS.1770-3 scale.
It is, therefore, suggested that when distributing Podcast or Mobile TV, to use a target level no lower than -16 LKFS. The easiest and best-sounding way to accomplish this is to:
[– Normalize to target level (-24 LKFS)
[– Limit peaks to -9 dBTP (Units for measurement of true peak audio level, relative to full scale)
[– Apply a gain change of +8 dB
Following this procedure, the distinction between foreground and background isn’t blurred, even on low-headroom platforms.”
Here is my interpretation of the steps referenced in the described workflow:
Step 1 – Normalize to target level -24.0 LUFS. (Notice Mr. Lund refers to LKFS instead of LUFS. No worries. Both are the same. LKFS translates to Loudness Units K-Weighted relative to Full Scale).
So how do we accomplish this? Simple – the source file needs to be measured and the existing Program Loudness needs to be established. Once you have this descriptor, it’s simple math. You calculate the difference between the existing Program Loudness and -24.0. The result will give you the initial gain offset that you need to apply.
I’ll point to a few off-line measurement utilities at the end of this post. Of course you can also measure in real time (on-line). In this case you would need to measure the source in it’s entirety in order to arrive upon an accurate Program Loudness measurement.
Keep in mind since random Program Loudness descriptors at the source will vary on a file to file basis, the necessary gain offset to normalize will always be different. In essence this particular step is variable. Conversely steps 2 and 3 in the workflow are static processes. They will never change. The Limiter Ceiling will always be -9.0 dBTP, and the final gain stage will always be + 8dB. The -16.0 LUFS target “math” will only work if the Program Loudness is -24.0 LUFS at the very beginning from file to file.
Think about it – with the Limiter and final gain stage never changing, – if you have two source files where file A checks in at -19.0 LUFS and File B checks in at -21.0 LUFS, the processed outputs will not be the same. On the other hand if you always begin with a measured Program Loudness of -24.0 LUFS, you will be good to go.
Examples:
[– If your source file checks in at -20.0 LUFS … with -24.0 as the target, the gain offset would be -4.0 dB.
[– If your source file checks in at -15.6 LUFS … with -24.0 as the target, the gain offset would be -8.4 dB.
[– If your source file checks in at -26.0 LUFS … with -24.0 as the target, the gain offset would be +2.0 dB.
[– If your source file checks in at -27.3 LUFS … with -24.0 as the target, the gain offset would be +3.3 dB
In order to maintain accuracy, make sure you use the float values in the calculation. Also – it’s important to properly optimize the source file (see example below) before performing Step 1. I’m referring to dynamics processing, equalization, noise reduction, etc. These options are for the most part subjective. For example if you prefer less compression resulting in wider dynamics, that’s fine. Handle it accordingly.
Moving forward we’ve established how to calculate and apply the necessary gain offset to Loudness Normalize the source audio to -24.0 LUFS. On to the next step …
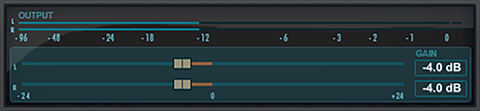
Step 2 – Pass the processed audio through a True Peak Limiter with it’s Peak Ceiling set to -9.0 dBTP. Typically I set the Channel or “Stereo” Link to 100%, limiting Look Ahead to 1.5ms and Release Time to 150ms.
Step 3 – Apply +8dB of gain.
You’re done.
You can set this up as an on-line process in a DAW, like this:
I’m using the gain adjustment feature in two instances of the Avid Time Adjuster plugin for the initial and final gain offsets. The source file on the track was first measured for Program Loudness. The necessary offset to meet the initial -24.0 LUFS target was -4 dB.
The audio then passes through the Nugen ISL True Peak Limiter with it’s Peak Ceiling set to -9.0 dBTP. Finally the audio is routed through the second instance of the Adjuster plugin adding +8 dB of gain. The Loudness meter displays the Program Loudness after 5 minutes of playback and will accurately display variations in Program Loudness throughout. Bouncing this session will output to the Normalized targets.
Note that you can also apply the initial gain offset, the limiting, and the final gain offset as independent off-line processes. The preliminary measurement of the audio file and gain offset are still required.
Example Workflow
Review the file attributes:
The audio is fairly dynamic. So I apply an initial stage of compression:
Next I apply additional processing options that I feel are necessary to create a suitable intermediate. I reiterate these processing options are entirely subjective. Your desire may be to retain the Loudness Range and/or dynamic attributes present in the original file. If so you will need to process the audio accordingly.
Here is the intermediate:
The Program Loudness for this intermediate file is -20.2 LUFS. The initial gain offset required would be -3.8 dB before proceeding.
After applying the initial gain offset, pass the audio through the limiter, and then apply the final gain stage.
This is the resulting output:
That’s about it. We’re at -16.0 LUFS with a suitable True Peak Max.
I’ve experimented with this workflow countless times and I’ve found the results to be perfectly acceptable. As I previously stated – preparation of your source or intermediate file prior to implementing this three step process is subjective and totally up to you. The key is your output will always be in spec..
Offline Measuring Tools
I can recommend the following tools to measure files “off-line.” I’m sure there are many other options:
[– Auphonic Leveler Batch Processor. I don’t want to discount the availability and effectiveness of the products and services offered by Auphonic. It’s a highly recommended web service and the standalone application that includes high quality audio processing algorithms including Loudness Normalization.



.jpg)
.jpg)
.jpg)
.jpg)